


자바의 개념, 기본 자료형에서 인터페이스에 이르고, 지난 시간에는 다루지 못했던 추상 클래스까지 포괄적으로 살펴보도록 하겠습니다. 그리고 이제 꽤 많은 자바 문법을 습득하였으므로, 실전 자바 프로그래밍 과정을 진행하며 본격적으로 버전 관리 도구인 Git도 함께 사용하면서 학습해 보도록 하겠습니다 😃
자바의 기본 자료형과 참조 자료형
- 정수형(int)
: 정수값을 저장할 때 가장 일반적으로 사용되는 타입은 int입니다. 예를 들어, 국어, 수학, 영어, 과학, 사회 등 각 과목의 시험 점수를 저장할 때 int 타입을 사용하면 적절합니다.
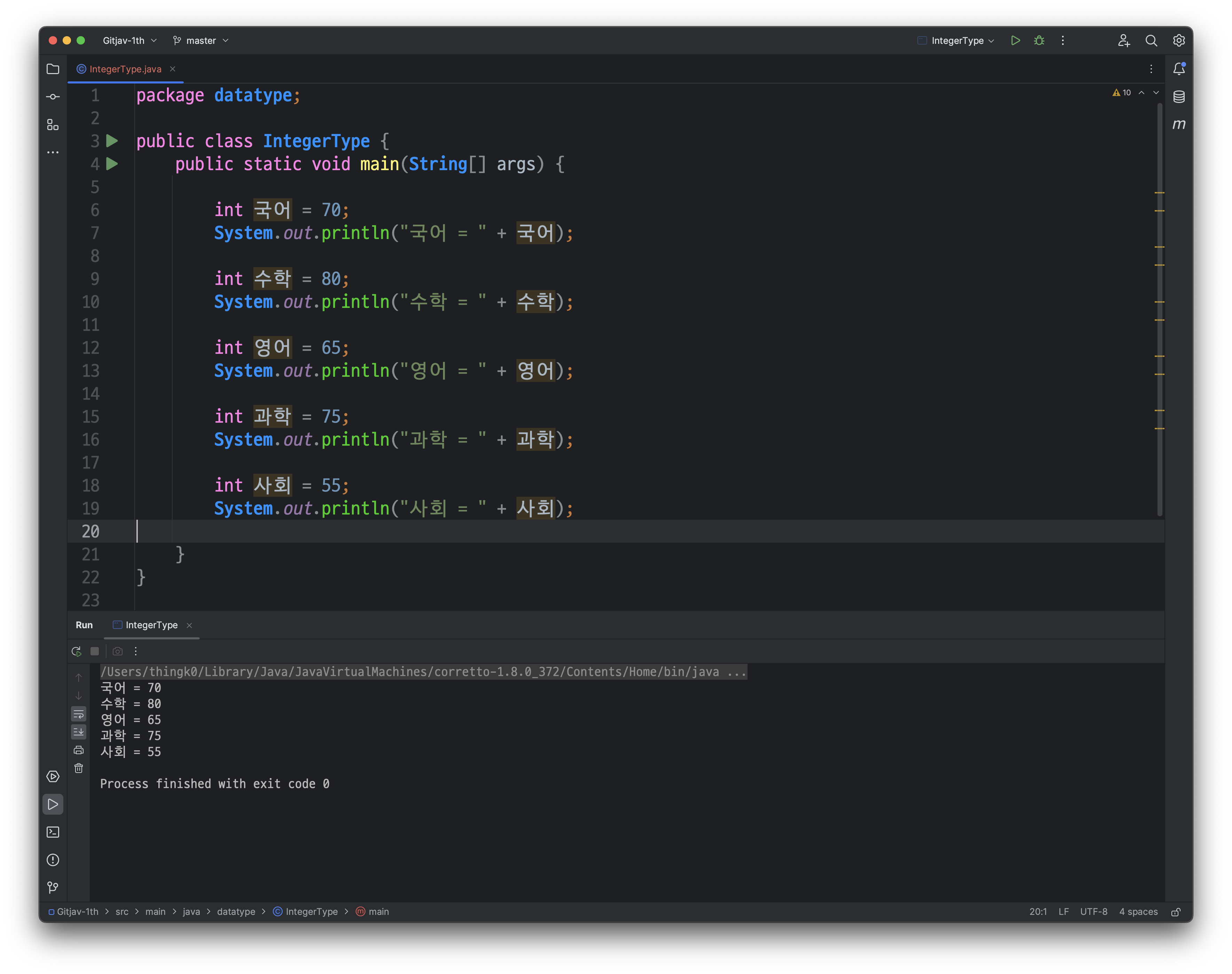
프로그래밍 언어에서 int 타입을 기본으로 사용하는 이유는 다음과 같습니다:
- 일반적인 사용 범위
: int 타입은 대부분의 사용 사례에서 충분한 크기의 정수를 나타낼 수 있습니다. 따라서, 일반적인 프로그래밍 작업에서는 int를 사용하면 효율적이고 간단한 코드를 작성할 수 있습니다. - 연산 효율
: 현대의 컴퓨터 아키텍처에서는 32비트 또는 64비트 정수 연산이 가장 효율적입니다. int 타입은 보통 32비트 정수를 나타내므로 이러한 컴퓨터에서 효율적으로 연산할 수 있습니다. byte와 short 같은 작은 크기의 정수 타입은 연산 시 일반적으로 내부적으로 int로 캐스팅되어 처리되기 때문에, 연산 효율에 차이가 없을 수도 있습니다. - 가독성
: int는 대부분의 프로그래밍 언어에서 정수 타입의 기본 값이므로, 개발자들이 이해하기 쉽고 코드의 가독성이 높습니다.
추가로, byte와 short 같은 작은 크기의 정수 타입을 사용하지 않는 이유는 다음과 같습니다:
- 저장 공간 절약
: 작은 크기의 정수 타입을 사용하면 메모리를 절약할 수 있습니다. 하지만 현대의 컴퓨터 시스템에서는 메모리 공간이 상대적으로 넉넉하므로, 이러한 절약 효과가 크지 않습니다. - 범위 제한
: byte와 short는 int에 비해 표현할 수 있는 정수 범위가 제한적입니다. 이로 인해 범위를 초과하는 경우 오버플로우가 발생할 수 있습니다. 따라서, 사용 사례에 맞는 적절한 정수 타입을 선택하는 것이 중요합니다.
byte, short, int, long 등의 정수 타입을 사용할지 결정할 때는 사용 사례에 따라 선택해야 합니다. 저장 공간의 절약이 중요한 경우나 작은 정수 범위가 필요한 경우 byte나 short를 사용할 수 있지만, 대부분의 경우 int 타입이 좋은 기본값입니다.
- 문자형(char)
: 'char' 타입은 문자(예: 알파벳, 숫자, 기호 등)를 나타내기 위해 사용되며, 문자 데이터의 처리와 저장을 간편하고 효율적으로 수행할 수 있는 목적을 가지고 있습니다.
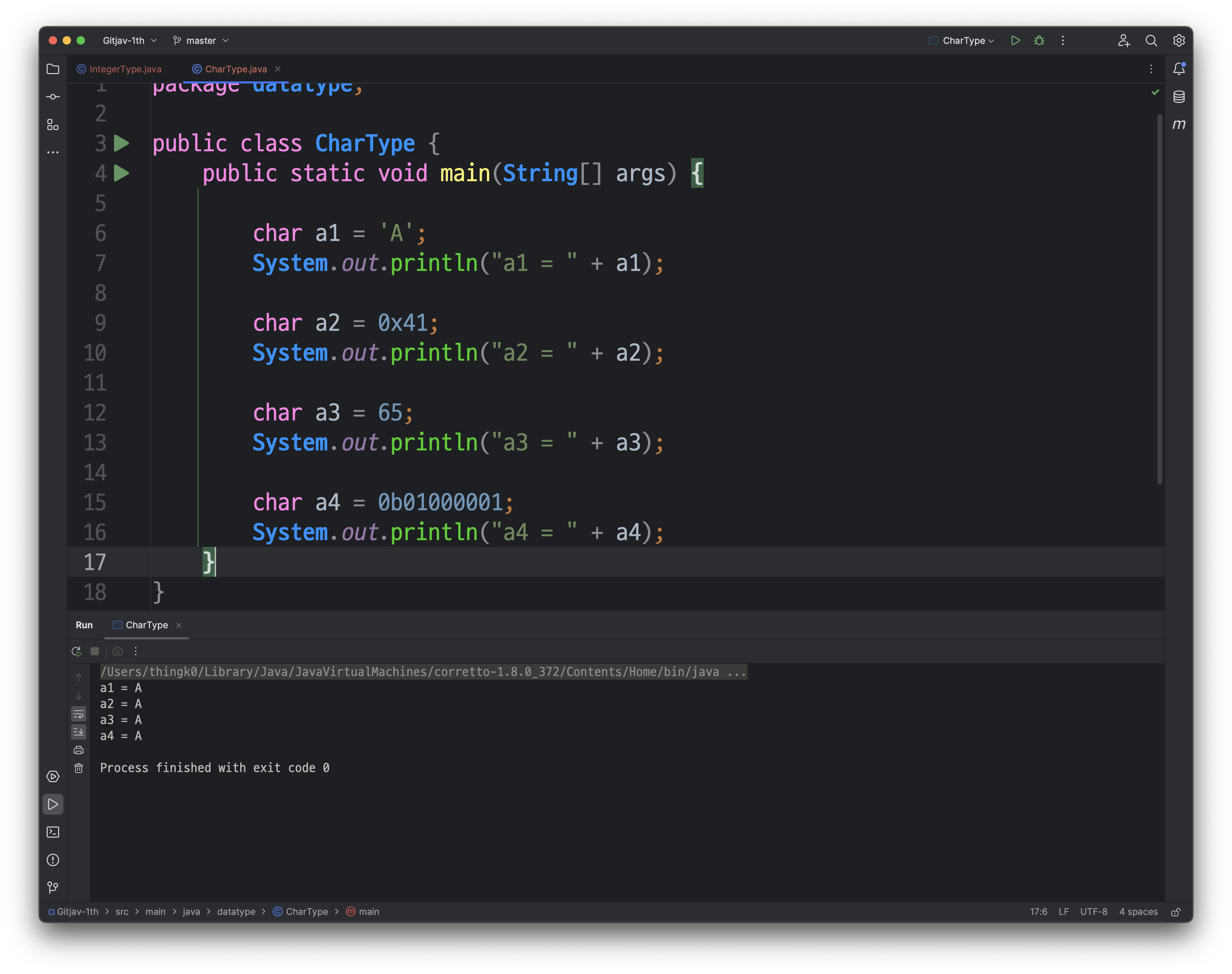
위 코드는 각각 다른 방법으로 'A'를 담은 char 변수를 선언하고 출력하는 구문입니다.
첫째 줄은 문자 리터럴 'A'를 char 변수 a1에 대입하는 것입니다. 'A'의 아스키코드 값은 65이며, 따라서 a1 변수에는 65가 저장됩니다.
둘째 줄에서는 0x41(16진수)을 char 변수 a2에 대입하고 있습니다. 16진수 0x41은 10진수로 65에 해당하는데, 이는 아스키코드에서 A의 값과 같으므로 a2 변수에도 65가 저장됩니다. 셋째 줄에서는 65라는 10진수를 char 변수 a3에 대입하고 있습니다. 65는 아스키코드에서 A의 값과 같으므로 a3 변수에도 65가 저장됩니다. 마지막 줄에서는 2진수 리터럴인 0b01000001을 char 변수 a4에 대입하고 있습니다. 이는 10진수 65에 해당하는데, 마찬가지로 아스키코드에서 A의 값과 같으므로 a4 변수에도 65가 저장됩니다.
따라서 위 코드의 출력 결과는 모두 'A'가 됩니다.
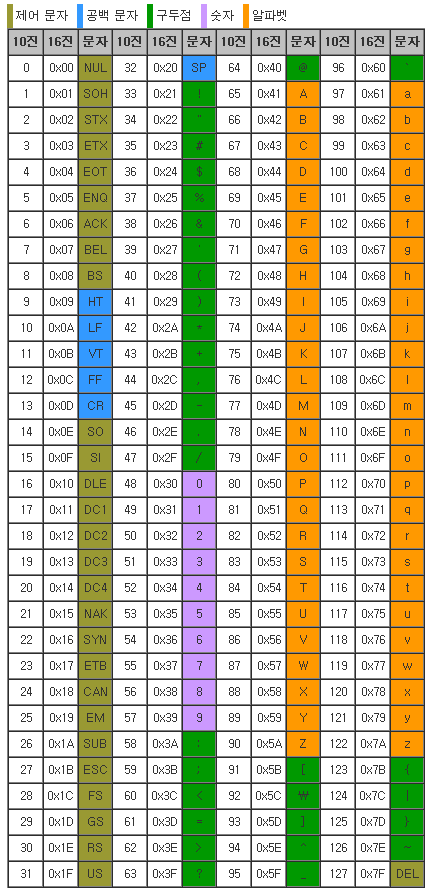
아스키코드(ASCII)
프로그래밍을 할 때 ASCII 코드를 알아야 하는 이유는 다음과 같습니다.
- ASCII 코드는 컴퓨터에서 문자를 표현하는 데 사용되는 가장 기본적인 코드이기 때문입니다.
- 대부분의 프로그래밍 언어와 운영 체제에서 ASCII 코드를 지원하기 때문입니다.
- 텍스트 파일이나 HTML 문서와 같은 다양한 유형의 파일에서 ASCII 코드를 사용하기 때문입니다.
예를 들어, ASCII 코드를 사용하여 특정 문자를 출력하거나, 특정 문자열에 대한 길이를 구하거나, 특정 문자열이 다른 문자열과 일치하는지 확인할 수 있습니다.
- 논리형(Boolean)
: 논리형 데이터 유형은 True 또는 False의 두 가지 값만 가질 수 있습니다. `true` 는 참을 나타내고 `false` 는 거짓을 나타냅니다. 논리형 데이터 유형은 조건문이나 논리 연산자와 같은 논리 연산에 자주 사용됩니다.
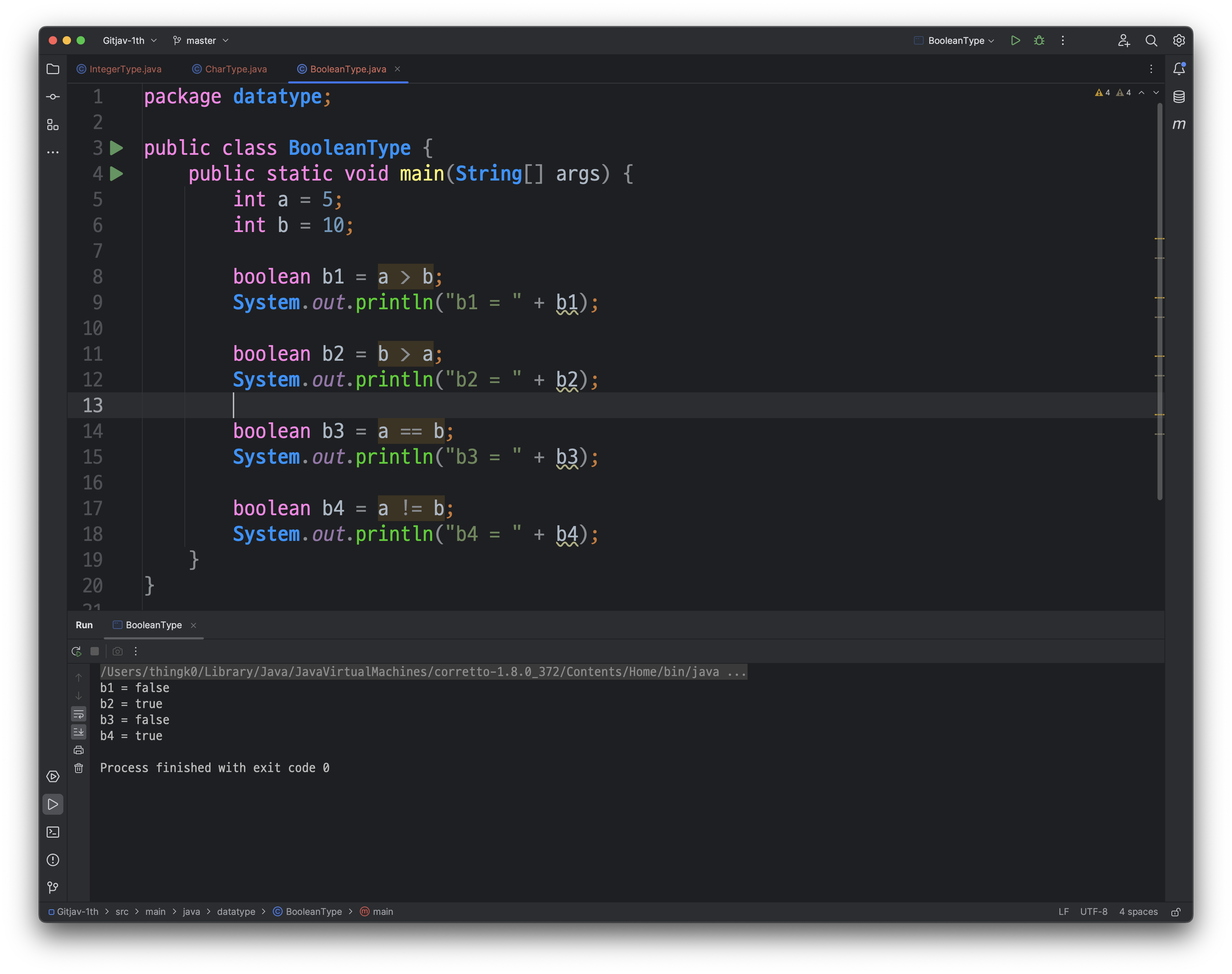
해당 코드는 두 개의 정수 a와 b를 비교하고, 그 결과를 boolean 변수에 저장하여 출력하는 코드입니다.
- boolean b1 = a > b
: a가 b보다 큰지를 판단하여 b1에 저장합니다. 만약 a가 b보다 크다면 b1은 true가 되고, 그렇지 않으면 false가 됩니다. - boolean b2 = b > a
: b가 a보다 큰지를 판단하여 b2에 저장합니다. 만약 b가 a보다 크다면 b2은 true가 되고, 그렇지 않으면 false가 됩니다. - boolean b3 = a == b
: a와 b가 같은지를 판단하여 b3에 저장합니다. 만약 a와 b가 같다면 b3은 true가 되고, 그렇지 않으면 false가 됩니다. - boolean b4 = a != b
: a와 b가 다른지를 판단하여 b4에 저장합니다. 만약 a와 b가 다르다면 b4은 true가 되고, 그렇지 않으면 false가 됩니다.
각 결과를 출력하는 부분은 "b1 = true", "b2 = false", "b3 = false", "b4 = true"와 같이 결괏값을 출력합니다.
- 실수형(Float)
: 실수형 데이터 유형은 값이 소수점을 포함할 수 있는 데이터 유형입니다. 자바에서 실수형 데이터 유형은 `float`와 `double`의 두 가지가 있습니다. float는 32비트 부동 소수점 숫자이고 double은 64비트 부동 소수점 숫자입니다. double은 float보다 더 많은 정확성과 범위를 가지므로 일반적으로 실수형 데이터를 저장하는 데 사용됩니다.
부동소수점은 컴퓨터에서 실수를 표현하는 방법 중 하나입니다. 실수는 소수점 이하의 수를 가지므로, 이를 이진수로 변환하면 유한 개의 비트로는 정확하게 표현하기 어렵습니다. 이때, 부동소수점은 소수점의 위치를 유동적으로 조절하여 실수를 근사적으로 표현하는 방식입니다. 이렇게 함으로써, 실수 연산을 더욱 빠르게 수행할 수 있게 됩니다.
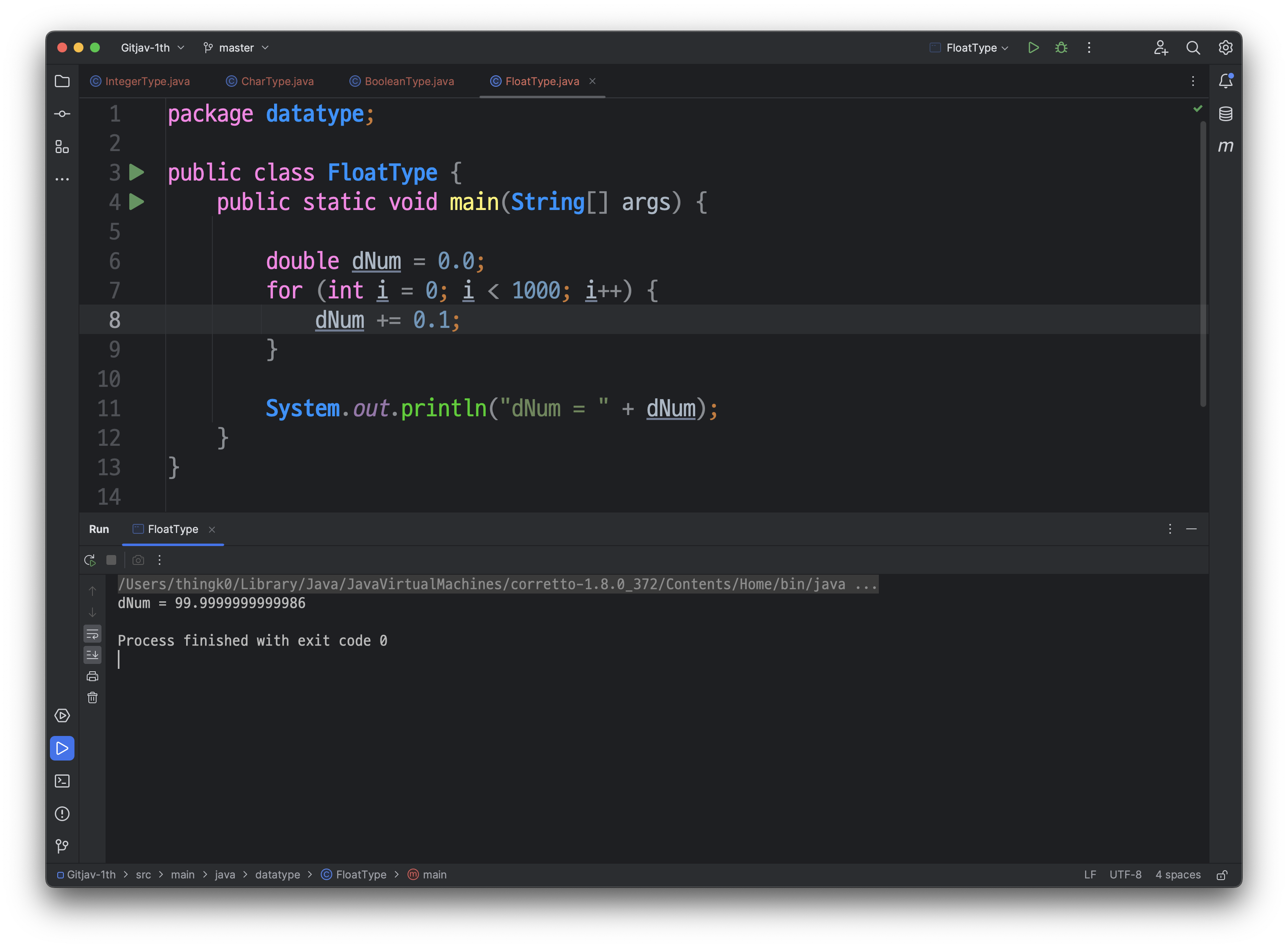
해당 코드는 0.1을 1000번 반복하여 더한 결과를 출력하는 코드입니다.
그러나, 출력 결과는 'dNum = 99.9999999999986' 와 같이 정확히 100.0이 아닌 값이 출력됩니다. 이는 부동 소수점 연산에서 발생하는 반올림 오차로 인한 결과입니다. 부동 소수점은 이진수로 소수를 표현하는 방식으로, 정확히 0.1을 표현할 수 없습니다. 대신, 근삿값으로 표현되며 이 근삿값들이 누적되면 오차가 발생합니다. 따라서 반복문에서 0.1을 반복적으로 더하면서 오차가 누적되어 최종 결과인 dNum은 정확한 100.0이 아닌 가까운 근삿값으로 계산되어 출력됩니다.
이러한 부동 소수점 연산의 반올림 오차를 피하기 위해서는 부동 소수점 연산을 사용하는 경우에는 오차를 감안하고 계산해야 합니다. 또는, 정확한 계산이 필요한 경우에는 BigDecimal 등의 정확한 십진 연산을 지원하는 데이터 타입을 사용하는 것이 좋습니다.
변수와 상수
변수 (Variable)
: 변수는 데이터를 저장하는 메모리 공간의 이름입니다. 변수는 선언된 데이터 타입에 따라 값을 저장하고 변경할 수 있습니다. 변수는 값을 변경할 수 있기 때문에, 프로그램 실행 중에 변수의 값이 변할 수 있습니다. 변수를 선언하려면 데이터 타입과 변수 이름을 사용하여 선언하고 초기화합니다.
// 정수형 변수 'age' 선언 및 초기화
int age = 25;
// 문자열 변수 'name' 선언 및 초기화
String name = "John Doe";변수명은 다음과 같은 조건을 충족해서 만들어야 합니다.
변수명은 가능한 짧고 간결하게 지정하세요. 변수명은 영문자로 시작하고, 영문자, 숫자, 언더스코어(_)를 사용할 수 있습니다.
변수의 의미를 잘 나타낼 수 있도록 이름을 지정하세요. 변수가 하나의 단어일 경우에는 소문자로, 여러 단어를 사용할 경우에는 카멜 케이스(camelCase) 혹은 스네이크 케이스(snake_case)를 사용하세요.
예를 들어, "사용자 이름"을 나타내는 변수를 만든다고 가정해 봅시다. 변수명으로는 "userName" 또는 "user_name"이 적합합니다. 이렇게 변수명을 지정하면 읽기 쉽고 변수의 의미를 파악하기 쉽습니다.
카멜 케이스 예시 5가지:
isUserLoggedIn / getCustomerName / calculateTotalOrderAmount
saveProductToDatabase / findClosestStore
스네이크 케이스 예시 5가지:
is_user_logged_in / get_customer_name / calculate_total_order_amount
save_product_to_database / find_closest_store
상수 (Constant)
: 상수는 값을 변경할 수 없는 변수입니다. 즉, 한 번 값을 할당하면 프로그램 실행 동안 그 값을 변경할 수 없습니다. 자바에서 상수를 선언하기 위해서는 final 키워드를 사용하여 변수를 선언합니다. 상수 이름은 일반적으로 모두 대문자로 작성합니다.
// 정수형 상수 'MAX_AGE' 선언 및 초기화
final int MAX_AGE = 120;
// 문자열 상수 'GREETING_MESSAGE' 선언 및 초기화
final String GREETING_MESSAGE = "Hello, World!";리터럴(literal)은 소스 코드에서 사용되는 고정된 값을 의미하는 프로그래밍 용어입니다. 리터럴은 변수에 값을 할당하거나, 수식에 사용하거나, 함수의 인자로 전달될 수 있습니다.
리터럴은 일반적으로 다양한 유형으로 구분되며, 주요 리터럴 유형에는 다음과 같은 것들이 있습니다:
정수형 리터럴(Integer literals)
: 정수 값의 표현으로, 10진법 또는 16진법 형태로 나타낼 수 있습니다. 예: 42 (10진법), 0x2A (16진법)
부동 소수점 리터럴(Floating-point literals)
: 소수점이 있는 숫자 값을 표현합니다. 예: 3.14, 1.5e-3 (지수 표기법)
문자 리터럴(Character literals)
: 개별 문자를 표현하는 데 사용되며 작은따옴표(')로 표시됩니다. 예: 'A', 'b', '1'
문자열 리터럴(String literals)
: 하나 이상의 문자로 구성된 텍스트를 표현하며 큰 따옴표(")로 묶입니다. 예: "Hello, world!", "안녕하세요!"
논리 리터럴(Boolean literals)
: 참(True) 또는 거짓(False) 값을 표현합니다. 예: true, false
널(null) 리터럴:
값이 없음을 나타내는 특수한 리터럴로, 보통 객체 참조가 아무것도 가리키지 않을 때 사용됩니다. 예: null
상수 풀(Constant Pool)
상수 풀(Constant Pool)은 자바의 메모리 영역 중 하나로, 클래스나 인터페이스에 사용되는 리터럴 값과 기호 참조를 저장하는 공간입니다. 상수 풀은 자바의 힙(Heap) 영역에 위치하며, 컴파일 시 생성됩니다.
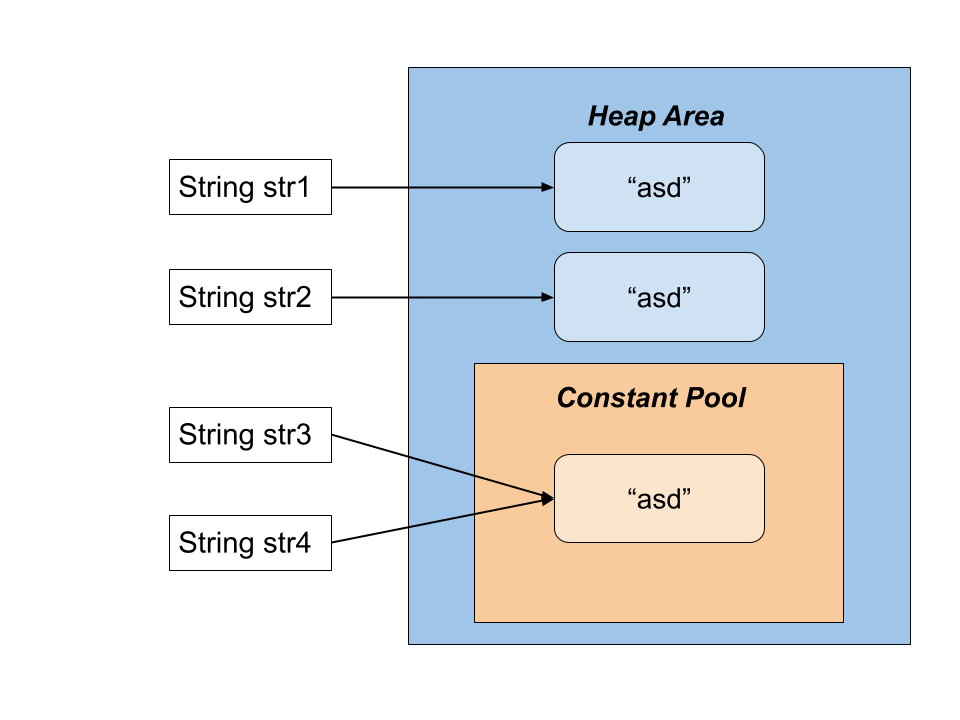
상수 풀의 주요 목적은 중복 데이터를 최소화하고 메모리 사용량을 줄이는 것입니다. 상수 풀을 사용하면 동일한 값이 여러 번 사용될 때마다 메모리에 새로운 객체를 생성하지 않고, 상수 풀에 있는 값을 재사용할 수 있습니다. 이로 인해 프로그램의 실행 효율이 향상됩니다.
자바에서 가장 대표적인 상수 풀의 사용 사례는 '문자열 리터럴' 입니다. 문자열 리터럴은 컴파일 시 상수 풀에 저장되며, 동일한 문자열 리터럴이 여러 번 사용될 경우 상수 풀의 값을 공유합니다.
예시:
String str1 = "Hello, World!";
String str2 = "Hello, World!";
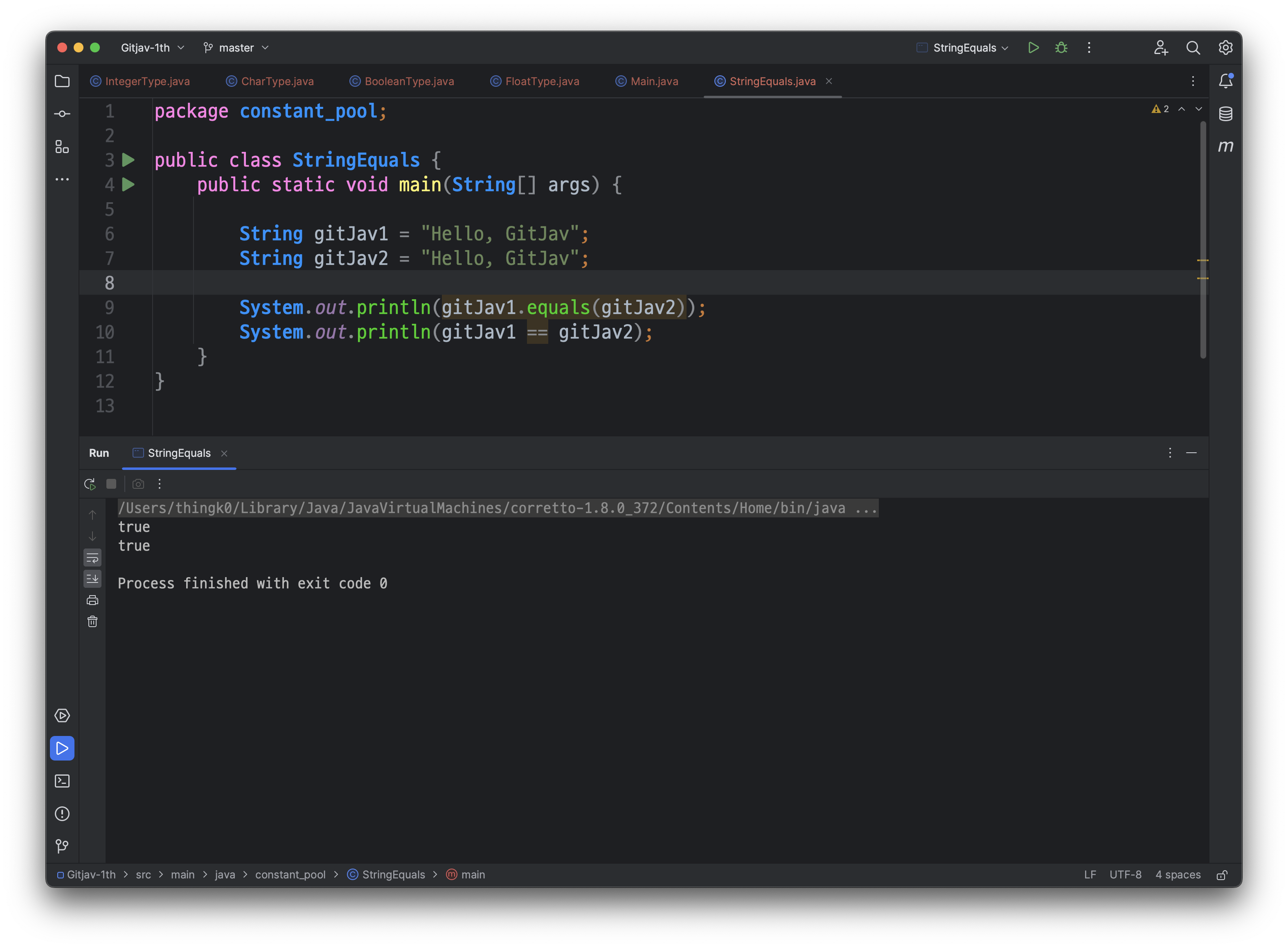
위 코드에서 str1과 str2는 동일한 문자열 리터럴 "Hello, World!"를 참조합니다. 컴파일 시 이 문자열 리터럴은 상수 풀에 저장되고, 두 변수는 상수 풀에 있는 동일한 문자열 객체를 참조하게 됩니다. 이렇게 상수 풀을 사용하면 메모리 사용량을 줄이고 프로그램의 실행 효율을 향상시킬 수 있습니다.
연산자(Opertaion)
- 산술 연산자(Arithmetic Operators): 수학적 연산을 수행하는 데 사용됩니다.
- +: 덧셈
- -: 뺄셈
- *: 곱셈
- /: 나눗셈
- %: 나머지
- 비교 연산자(Comparison Operators): 두 값의 비교를 수행하는 데 사용됩니다. 결과는 true 또는 false입니다.
- ==: 동일함
- !=: 동일하지 않음
- >: 큼
- <: 작음
- >=: 크거나 같음
- <=: 작거나 같음
- 논리 연산자(Logical Operators): 논리적 조건을 검사하는 데 사용됩니다. 결과는 true 또는 false입니다.
- &&: AND (논리곱)
- ||: OR (논리합)
- !: NOT (논리부정)
- 비트 연산자(Bitwise Operators): 비트 수준에서 작동하는 연산자입니다.
- &: 비트 AND
- |: 비트 OR
- ^: 비트 XOR
- ~: 비트 NOT
- <<: 비트 왼쪽 시프트
- >>: 비트 오른쪽 시프트
- >>>: 비트 오른쪽 논리 시프트 (부호 비트를 고려하지 않음)
- 할당 연산자(Assignment Operators): 변수에 값을 할당하는 데 사용됩니다.
- =: 할당
- +=: 덧셈 후 할당
- -=: 뺄셈 후 할당
- *=: 곱셈 후 할당
- /=: 나눗셈 후 할당
- %=: 나머지 후 할당
- <<=: 비트 왼쪽 시프트 후 할당
- >>=: 비트 오른쪽 시프트 후 할당
- &=: 비트 AND 후 할당
- ^=: 비트 XOR 후 할당
- |=: 비트 OR 후 할당
- 증감 연산자(Increment and Decrement Operators): 변수의 값을 1 증가시키거나 감소시키는 데 사용됩니다.
- ++: 증가 연산자
- --: 감소 연산자
- 조건 연산자(Conditional Operator): 조건에 따라 두 가지 값을 선택하는 데 사용됩니다. 삼항 연산자라고도 불립니다.
- ? :: 조건식 ? 값1 : 값2 (조건식이 참이면 값1을 반환하고, 거짓이면 값2를 반환합니다)
- instanceof 연산자: 객체가 특정 클래스 또는 인터페이스의 인스턴스인지 확인하는 데 사용됩니다. 결과는 true 또는 false입니다.
- instanceof: 객체 변수 instanceof 클래스/인터페이스 이름
- 타입 캐스팅 연산자(Type Casting Operators): 한 데이터 타입을 다른 데이터 타입으로 변환하는 데 사용됩니다.
- (타입): 명시적 타입 캐스팅 (예: (int) 3.14)
이러한 연산자들은 다양한 조합으로 사용되어 프로그램의 로직을 구성합니다. 연산자들은 우선순위에 따라 실행되며, 괄호를 사용하여 실행 순서를 제어할 수 있습니다. 그리고 자바에서 연산자는 우선순위에 따라 실행됩니다. 우선순위가 높은 연산자가 먼저 실행됩니다. 우선순위가 같은 경우, 연산자 실행 순서는 좌에서 우로 진행됩니다.
자바에서 연산자 우선순위는 다음과 같습니다:
- 괄호()
- 후위 연산자++, 전위 연산자--, 단항 연산자(+, -, !, ~)
- 산술 연산자(*, /, %)
- 쉬프트 연산자(<<, >>, >>>)
- 관계 연산자(<, >, <=, >=, instanceof)
- 논리 연산자(&, ^, |)
- 논리 연산자(&&, ||)
- 조건 연산자(?:)
- 대입 연산자(=, +=, -=, *=, /=, %=, <<=, >>=, >>>=, &=, ^=, |=)
예를 들어, 다음과 같은 식이 있을 경우: int result = 3 + 8 * 2;
곱셈 연산자가 덧셈 연산자보다 우선순위가 높기 때문에, 8*2 먼저 실행됩니다. 따라서 result는 19가 됩니다.
하지만 만약 다음과 같은 식이 있다면: int result = (3 + 8) * 2;
괄호 안에 있는 덧셈 연산자가 먼저 실행되기 때문에, result는 22가 됩니다.
콘솔 출력
자바에서 콘솔 출력은 주로 System.out.println() 메서드와 System.out.print() 메서드를 사용하여 표준 출력 스트림(콘솔)에 데이터를 출력하는 데 사용됩니다. 이들 메서드는 자바의 java.lang.System 클래스에 정의되어 있습니다.
System.out.println()
: 이 메소드는 전달된 인자를 콘솔에 출력한 후 줄 바꿈(newline)을 수행합니다. 따라서 다음 출력 내용이 새로운 줄에 표시됩니다. println() 메서드는 문자열, 정수, 실수, 문자, 불리언 등 다양한 데이터 타입을 인자로 받을 수 있습니다.
System.out.println("Hello, World!");
System.out.println(42);
System.out.println(3.14);
System.out.println('A');
System.out.println(true);
System.out.print()
: 이 메소드는 전달된 인자를 콘솔에 출력하지만 줄 바꿈을 수행하지 않습니다. 따라서 이어지는 출력 내용이 같은 줄에 이어서 표시됩니다. print() 메서드 역시 다양한 데이터 타입을 인자로 받을 수 있습니다.
System.out.print("Hello, ");
System.out.print("World!");
System.out.print(42);
System.out.print(3.14);
System.out.print('A');
System.out.print(true);
System.out.printf()
또한 System.out.printf() 메소드를 사용하여 형식화된 문자열을 출력할 수도 있습니다. printf() 메소드는 C언어의 printf 함수와 유사하게 동작하며, 형식 지정자(format specifiers)를 사용하여 출력 형식을 제어할 수 있습니다.
int age = 20;
String name = "Gildong Hong";
System.out.printf("My name is %s, and I am %d years old.", name, age);
형식 지정 문자
- %s : 문자열(string)
- %d : 십진수(decimal integer)
- %o : 8진수(octal integer)
- %x, %X : 16진수(hexadecimal integer). %x는 소문자이고, %X는 대문자입니다.
- %f : 부동 소수점(floating point number)
- %e, %E : 지수 표현(exponential)의 부동 소수점(floating point number). %e는 소문자이고, %E는 대문자입니다.
- %g, %G : 일반 형식(general format)의 부동 소수점(floating point number). %g는 값에 따라 %f 또는 %e를 사용하고, %G는 값에 따라 %f 또는 %E를 사용합니다.
- %c : 문자(character)
- %b : 논리(boolean)
- %t : 날짜/시간(date/time)
- %% : % 기호(literal % character)
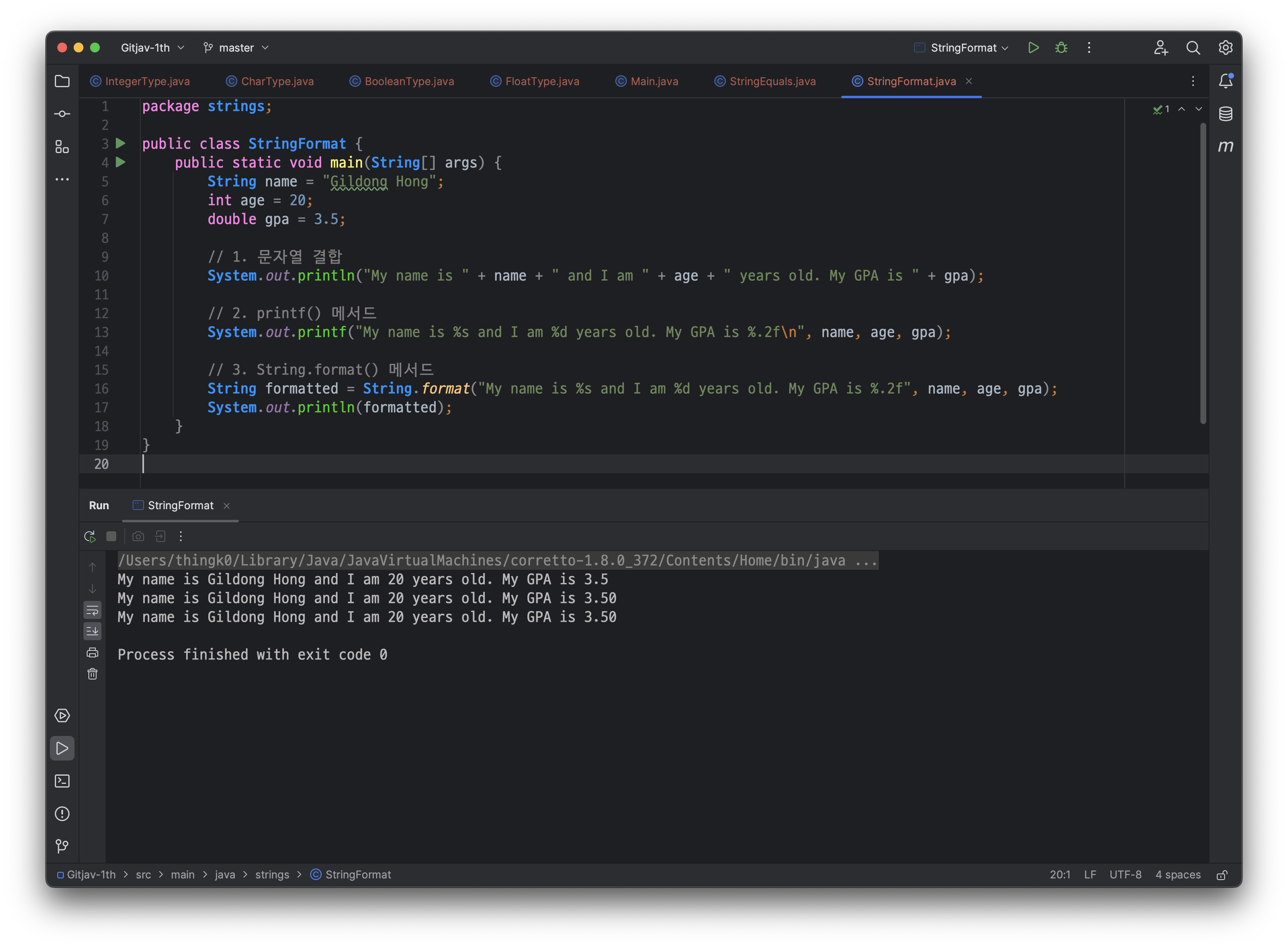
String name = "Gildong Hong";
int age = 20;
double gpa = 3.5;
// 1. 문자열 결합
System.out.println("My name is " + name + " and I am " + age + " years old. My GPA is " + gpa);
// 2. printf() 메서드
System.out.printf("My name is %s and I am %d years old. My GPA is %.2f\n", name, age, gpa);
// 3. String.format() 메서드
String formatted = String.format("My name is %s and I am %d years old. My GPA is %.2f", name, age, gpa);
System.out.println(formatted);
이 외에도 다양한 형식 지정 문자가 있습니다. 예를 들어, %5d는 최소 필드 너비(minimum field width)가 5인 십진수(decimal integer)를 출력하고, %+d는 부호(sign)가 있는 십진수(decimal integer)를 출력합니다.
형식 지정 문자를 사용할 때, 대부분 % 기호와 문자 사이에 옵션을 추가할 수 있습니다. 예를 들어, %5.2f는 최소 필드 너비가 5이고 소수점 이하 두 자리까지 출력하는 부동 소수점(floating point number)을 출력합니다. 여기서 최소 필드 너비는 출력 문자열의 최소 길이를 나타냅니다.
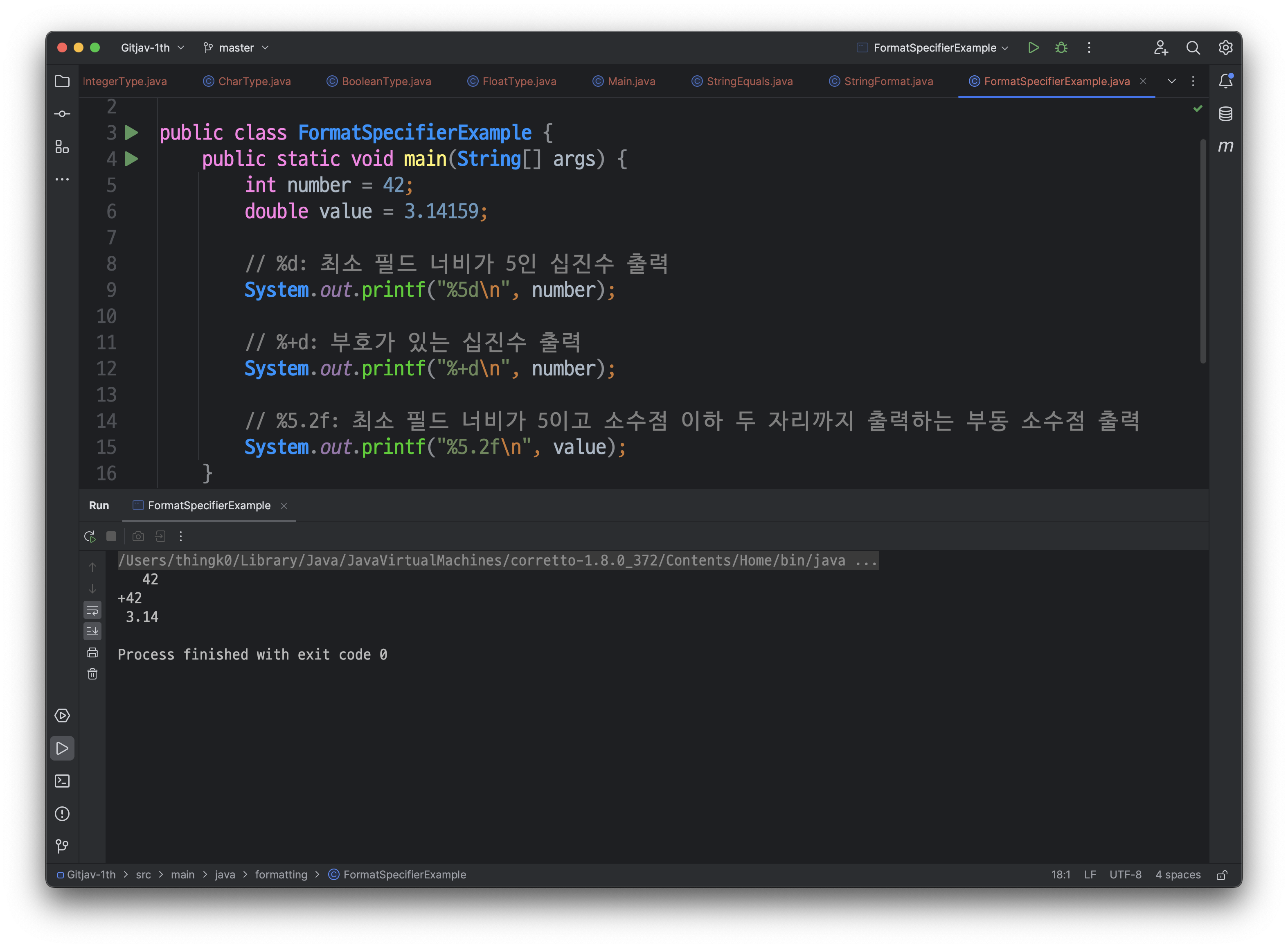
첫 번째 printf 문은 %5d 형식 지정 문자를 사용하여 number 변수를 출력합니다. 최소 필드 너비가 5이므로 출력 문자열은 오른쪽 정렬되고, 필요한 경우 왼쪽에 공백이 추가됩니다.
두 번째 printf 문은 %+d 형식 지정 문자를 사용하여 number 변수를 출력합니다. 부호가 있는 십진수를 출력하기 때문에 양수인 경우에도 부호가 함께 출력됩니다.
세 번째 printf 문은 %5.2f 형식 지정 문자를 사용하여 value 변수를 출력합니다. 최소 필드 너비가 5이므로 출력 문자열은 오른쪽 정렬되고, 소수점 이하 두 자리까지 출력됩니다.
콘솔 입력
자바에서 콘솔 입력을 처리하기 위해 java.util.Scanner 클래스를 사용할 수 있습니다. Scanner 클래스는 다양한 유형의 입력을 읽을 수 있도록 도와주는 유용한 기능을 제공합니다. 이를 통해 사용자로부터 키보드를 통한 입력을 받을 수 있습니다.
아래는 콘솔 입력을 처리하는 간단한 예제입니다:
// Scanner 객체 생성
Scanner scanner = new Scanner(System.in);
System.out.print("이름을 입력하세요: ");
String name = scanner.nextLine(); // 한 줄의 문자열 입력 받기
System.out.print("나이를 입력하세요: ");
int age = scanner.nextInt(); // 정수 입력 받기
System.out.println("입력된 정보:");
System.out.println("이름: " + name);
System.out.println("나이: " + age);
// Scanner 사용이 끝났으면 닫아주는 것이 좋습니다.
scanner.close();위 코드는 사용자로부터 이름과 나이를 입력받아 출력하는 예제입니다. Scanner 클래스의 nextLine() 메서드는 한 줄의 문자열을 입력받고, nextInt() 메서드는 정수를 입력받습니다.
프로그램을 실행하면 콘솔에서 사용자로부터 이름과 나이를 입력할 수 있는 프롬프트가 표시됩니다. 사용자가 입력한 내용은 name과 age 변수에 저장되어 이후에 사용됩니다. 입력된 정보는 마지막에 출력됩니다.
제어문 (Control statement)
if 문
int number = 10;
if (number > 0) {
System.out.println("양수입니다.");
}위의 예시에서, number 변수의 값이 0보다 크므로 조건식이 참이 되어 "양수입니다."가 출력됩니다.
if-else 문
int number = -5;
if (number > 0) {
System.out.println("양수입니다.");
} else {
System.out.println("음수입니다.");
}위의 예시에서, number 변수의 값이 0보다 작으므로 조건식이 거짓이 되어 "음수입니다."가 출력됩니다.
else-if 문
int number = 0;
if (number > 0) {
System.out.println("양수입니다.");
} else if (number < 0) {
System.out.println("음수입니다.");
} else {
System.out.println("0입니다.");
}위의 예시에서, number 변수의 값이 0이므로 첫 번째 조건식과 두 번째 조건식이 거짓이 되고, 따라서 "0입니다."가 출력됩니다.
switch 문
int choice = 2;
switch (choice) {
case 1:
System.out.println("1을 선택했습니다.");
break;
case 2:
System.out.println("2를 선택했습니다.");
break;
case 3:
System.out.println("3을 선택했습니다.");
break;
default:
System.out.println("유효하지 않은 선택입니다.");
break;
}위의 예시에서, choice 변수의 값이 2이므로 두 번째 case 레이블이 일치하고 "2를 선택했습니다."가 출력됩니다.
for 문
for (int i = 1; i <= 5; i++) {
System.out.println("반복: " + i);
}위의 예시에서, i 변수는 1부터 5까지 반복하며, 각 반복마다 "반복: "과 i의 값을 출력합니다.
while 문
int count = 0;
while (count < 5) {
System.out.println("카운트: " + count);
count++;
}위의 예시에서, count 변수가 5보다 작은 동안 반복하며, 각 반복마다 "카운트: "과 count의 값을 출력하고 count를 증가시킵니다.
do-while 문
int count = 0;
do {
System.out.println("카운트: " + count);
count++;
} while (count < 5);위의 예시에서, count 변수의 값을 출력하고 증가시키는 코드를 한 번 실행한 후, count가 5보다 작은 동안 반복됩니다.
break 문
for (int i = 1; i <= 10; i++) {
if (i == 5) {
break;
}
System.out.println(i);
}위의 예시에서, i 변수가 5가 되는 시점에서 break문이 실행되어 반복문이 중단됩니다. 따라서 1부터 4까지의 숫자가 출력됩니다.
continue 문
for (int i = 1; i <= 5; i++) {
if (i == 3) {
continue;
}
System.out.println(i);
}위의 예시에서, i 변수가 3이 되는 시점에서 continue문이 실행되어 해당 반복을 건너뜁니다. 따라서 1, 2, 4, 5가 출력됩니다.
return 문
public int addNumbers(int a, int b) {
int sum = a + b;
return sum;
}위의 예시에서, addNumbers 메서드는 두 개의 정수를 입력받아 합을 반환하는 메서드입니다. return 키워드를 사용하여 sum 변수의 값을 반환합니다.
메서드 (Method)
메서드(method)는 클래스 내에서 정의된 일련의 코드 블록으로, 특정 작업을 수행하는 데 사용됩니다. 메서드는 입력 매개변수를 받아들이고, 그에 따른 결과를 반환할 수도 있습니다. 메서드는 코드의 재사용성을 향상시키고, 구조화된 프로그래밍을 가능하게 합니다. 메서드는 객체 지향 프로그래밍(OOP)의 핵심 구성 요소 중 하나로, 클래스의 객체를 통해 호출되어 사용됩니다.
간단한 메서드 예시:
public class Calculator {
// 두 정수를 더하는 메서드
public int add(int a, int b) {
return a + b;
}
}위 예시에서, add라는 이름의 메서드가 정의되어 있으며, 두 개의 정수 인자를 받아들여 그 합을 반환하는 작업을 수행합니다. 이 메서드는 Calculator 클래스의 객체를 통해 호출됩니다.
ex) 미니 계산기 메서드
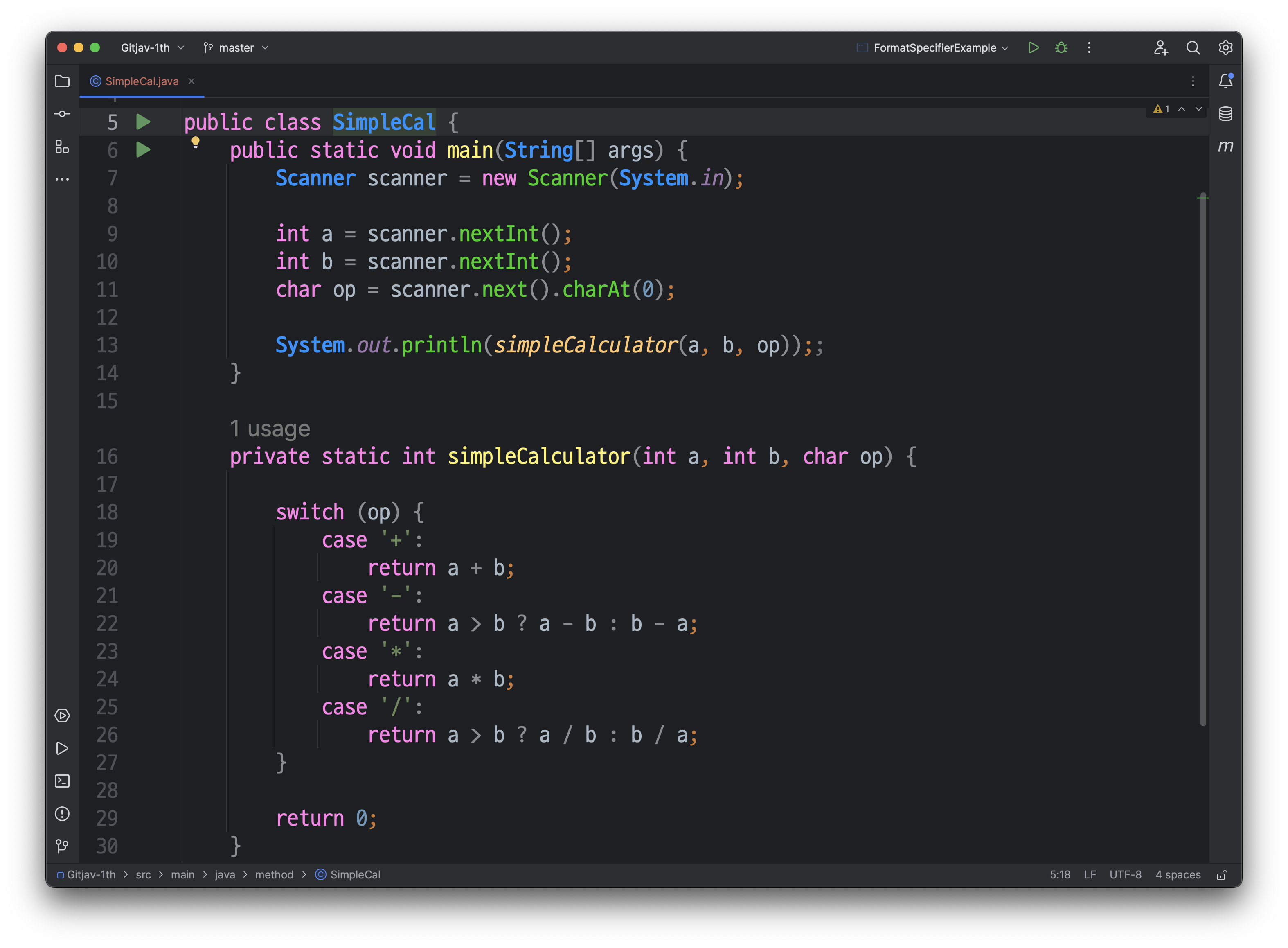
public class SimpleCal {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int a = scanner.nextInt();
int b = scanner.nextInt();
char op = scanner.next().charAt(0);
System.out.println(simpleCalculator(a, b, op));;
}
private static int simpleCalculator(int a, int b, char op) {
switch (op) {
case '+':
return a + b;
case '-':
return a > b ? a - b : b - a;
case '*':
return a * b;
case '/':
return a > b ? a / b : b / a;
}
return 0;
}
}
주어진 코드는 간단한 계산기를 구현하는 프로그램입니다. 사용자로부터 두 개의 정수와 연산자를 입력받고, 입력된 연산을 수행하여 결과를 출력합니다. 코드를 분석해 보도록 하겠습니다.
- Scanner 객체를 생성하여 사용자의 입력을 처리할 준비를 합니다.
- nextInt() 메서드를 사용하여 정수 a와 b를 입력받습니다.
- next().charAt(0) 를 사용하여 문자열에서 첫 번째 문자를 입력받습니다. 이 문자는 연산자를 나타내는 문자입니다.
- simpleCalculator() 메서드를 호출하여 입력된 정수와 연산자를 전달하고, 반환된 결과를 출력합니다.
- simpleCalculator() 메서드는 입력된 정수 a, b, 그리고 연산자 op에 따라서 계산을 수행합니다.
- op가 '+'인 경우 a + b를 반환합니다.
- op가 '-'인 경우 두 수의 차이인 a - b를 반환합니다. 이때, 절댓값을 사용하여 더 큰 수에서 작은 수를 빼도록 구현되었습니다.
- op가 '*'인 경우 a * b를 반환합니다.
- op가 '/'인 경우 두 수의 비율인 a / b를 반환합니다. 마찬가지로 절댓값을 사용하여 더 큰 수를 작은 수로 나누도록 구현되었습니다.
- 만약 op가 위의 네 가지 경우에 해당하지 않는다면, 0을 반환합니다.
이 프로그램은 사용자로부터 두 개의 정수와 연산자를 입력받아 해당 연산을 수행하고 결과를 출력하는 간단한 계산기 기능을 제공합니다.
ex) 삼각형 피라미드 메서드
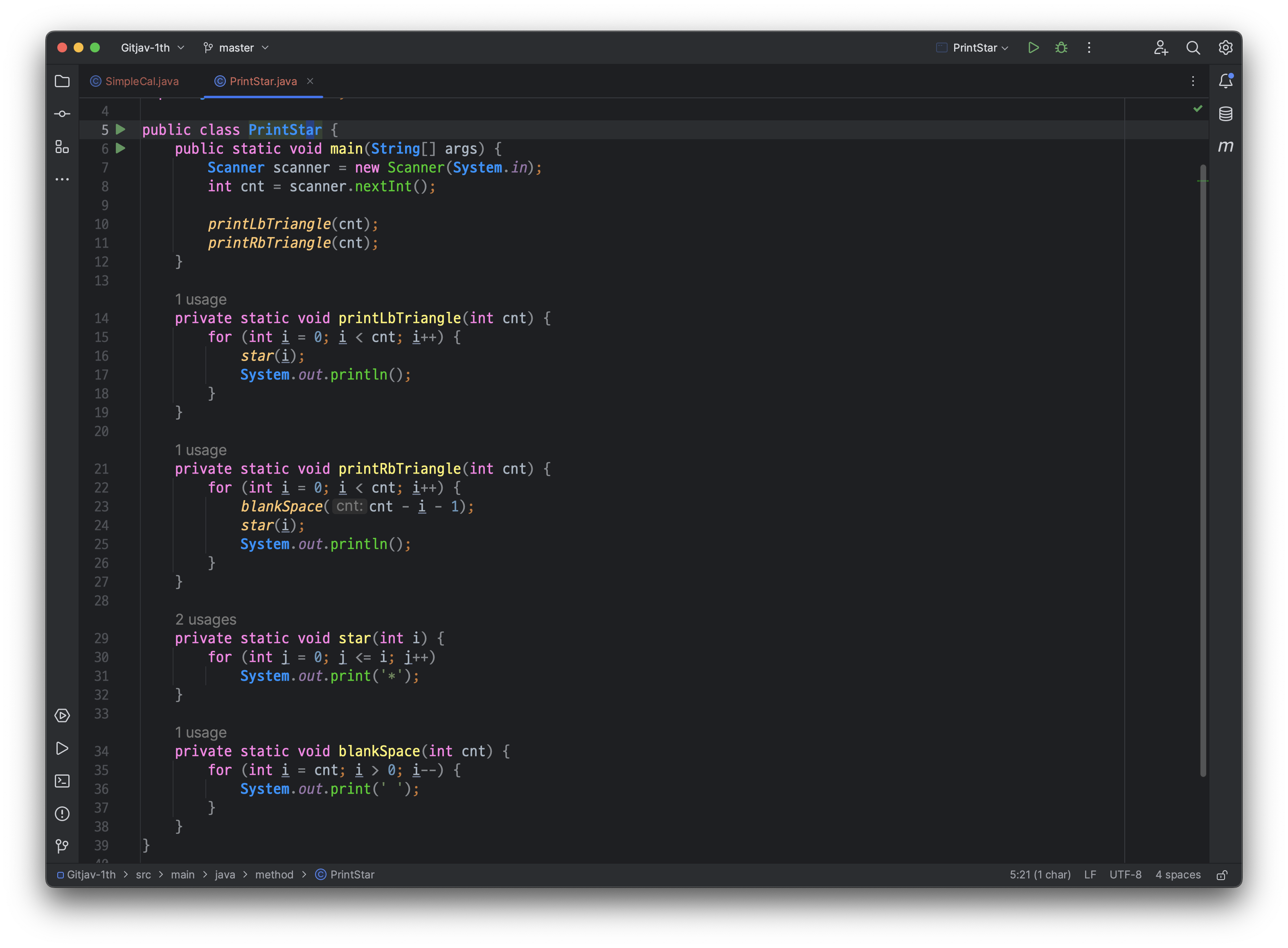
public class PrintStar {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int cnt = scanner.nextInt();
printLbTriangle(cnt);
printRbTriangle(cnt);
}
private static void printLbTriangle(int cnt) {
for (int i = 0; i < cnt; i++) {
star(i);
System.out.println();
}
}
private static void printRbTriangle(int cnt) {
for (int i = 0; i < cnt; i++) {
blankSpace(cnt - i - 1);
star(i);
System.out.println();
}
}
private static void star(int i) {
for (int j = 0; j <= i; j++)
System.out.print('*');
}
private static void blankSpace(int cnt) {
for (int i = cnt; i > 0; i--) {
System.out.print(' ');
}
}
}
주어진 코드는 사용자로부터 입력받은 숫자에 따라 좌측 아래 삼각형과 우측 아래 삼각형을 출력하는 프로그램입니다. 코드를 분석해 보도록 하겠습니다.
- Scanner 객체를 생성하여 사용자의 입력을 처리할 준비를 합니다.
- nextInt() 메서드를 사용하여 사용자로부터 입력받은 정수를 cnt 변수에 저장합니다.
- printLbTriangle() 메서드를 호출하여 좌측 아래 삼각형을 출력합니다. cnt 값에 따라 삼각형의 크기가 결정됩니다.
- printRbTriangle() 메서드를 호출하여 우측 아래 삼각형을 출력합니다. cnt 값에 따라 삼각형의 크기가 결정됩니다.
- printLbTriangle() 메서드는 좌측 아래 삼각형을 출력하는 역할을 합니다. 반복문을 사용하여 각 줄마다 star() 메서드를 호출하여 해당 줄에 별표(*)를 출력하고, 줄 바꿈을 수행합니다.
- printRbTriangle() 메서드는 우측 아래 삼각형을 출력하는 역할을 합니다. 반복문을 사용하여 각 줄마다 blankSpace() 메서드를 호출하여 해당 줄의 공백을 출력하고, 그다음에star() 메서드를 호출하여 해당 줄에 별표(*)를 출력하고, 줄 바꿈을 수행합니다. 이를 통해 우측 아래로 갈수록 공백이 늘어나는 모양을 만듭니다.
- star() 메서드는 주어진 i 값에 따라서 *을 출력합니다. i 값이 증가함에 따라 별표의 개수가 늘어나는 형태를 만듭니다.
- blankSpace() 메서드는 주어진 cnt 값에 따라서 공백을 출력합니다. cnt 값이 감소함에 따라 공백의 개수가 줄어드는 형태를 만듭니다.
이 프로그램은 사용자로부터 입력받은 숫자에 따라 좌측 아래 삼각형과 우측 아래 삼각형을 출력합니다.
클래스(Class)
- 클래스는 객체를 만들기 위한 틀 또는 설계도입니다.
- 클래스는 객체의 상태(속성)와 동작(메서드)을 정의합니다.
- 객체를 생성하기 위해 클래스는 특정한 구조와 특성을 가진 데이터와 메서드의 집합을 포함합니다.
- 클래스는 객체의 공통된 속성과 동작을 추상화하여 표현합니다.
- 객체를 생성하기 위한 템플릿이며, 여러 개의 객체를 생성할 수 있습니다.
객체(Object)
- 객체는 클래스의 인스턴스(Instance)입니다. 클래스에 정의된 속성과 동작을 실제로 가지고 있는 구체적인 개체입니다.
- 객체는 실제로 메모리에 할당되어 동작하며, 데이터와 메서드로 구성됩니다.
- 객체는 고유한 상태(속성)를 가지며, 이 상태는 객체가 가지는 데이터에 의해 결정됩니다.
- 객체는 클래스에 정의된 동작(메서드)을 수행할 수 있습니다.
- 클래스로부터 생성된 객체는 서로 독립적으로 동작하며, 객체 간에 메시지를 주고받을 수 있습니다.
간단히 말하면, 클래스는 객체를 만들기 위한 템플릿이며, 객체는 클래스의 인스턴스로 실제로 동작하는 개체입니다. 클래스는 객체의 구조와 특성을 정의하고, 객체는 클래스에 정의된 속성과 동작을 실제로 가지고 있습니다. 객체 지향 프로그래밍에서는 클래스와 객체를 활용하여 코드의 가독성과 재사용성을 높이고, 코드를 모듈화 하여 유지보수를 용이하게 합니다.
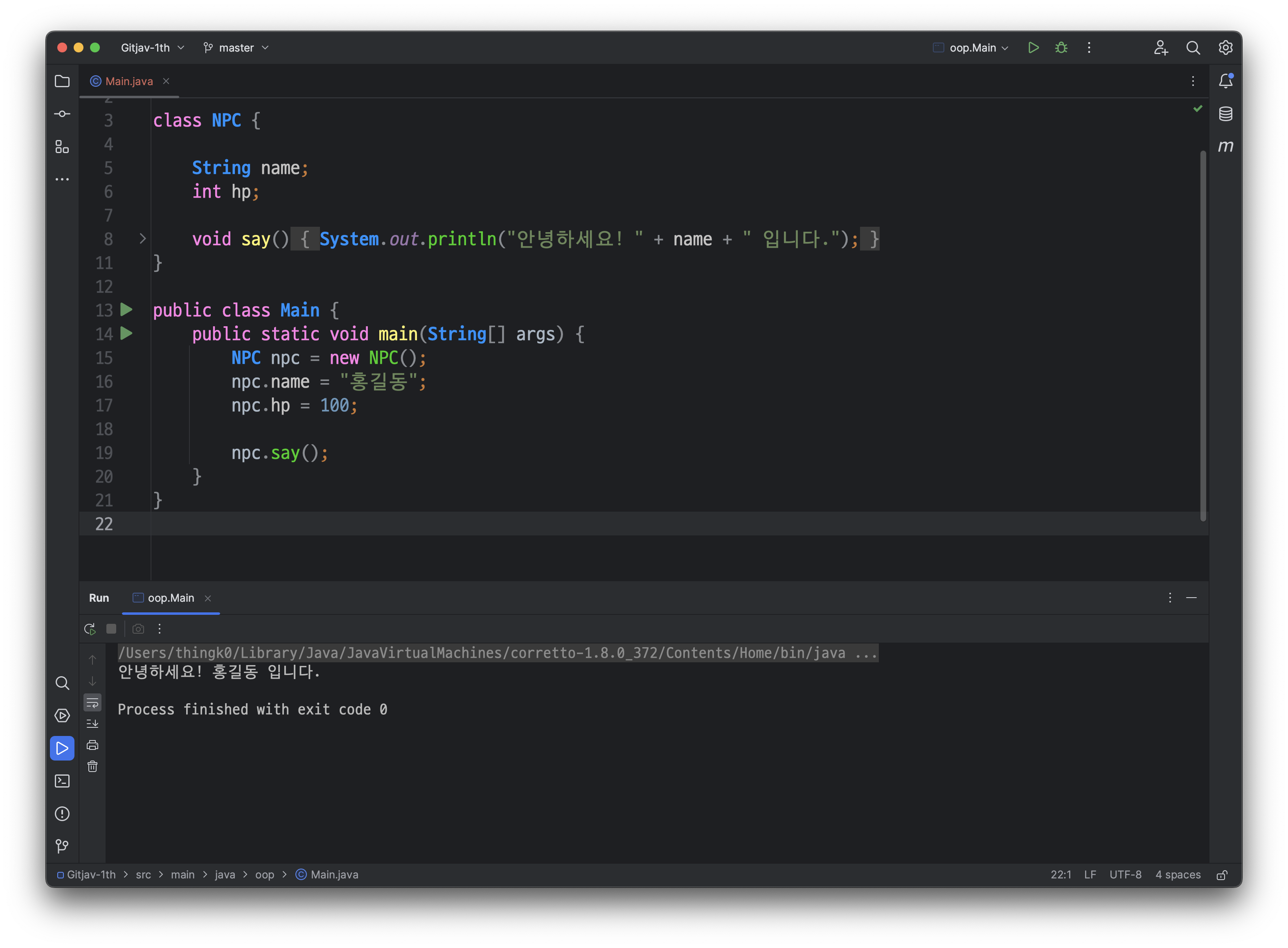
class NPC {
String name;
int hp;
void say() {
System.out.println("안녕하세요! " + name + " 입니다.");
}
}
public class Main {
public static void main(String[] args) {
NPC npc = new NPC();
npc.name = "홍길동";
npc.hp = 100;
npc.say();
}
}- NPC 클래스 정의:
- name과 hp라는 두 개의 멤버 변수를 가지고 있습니다. name은 NPC의 이름을 저장하고, hp는 NPC의 체력을 저장합니다.
- say() 메서드를 가지고 있습니다. 이 메서드는 NPC가 인사말을 출력하는 역할을 합니다.
- main 메서드:
- 먼저, NPC 클래스의 인스턴스인 npc를 생성합니다. npc는 NPC 클래스의 객체를 나타냅니다.
- npc.name에 "홍길동"을 대입하여 npc의 이름을 설정합니다.
- npc.hp에 100을 대입하여 npc의 체력을 설정합니다.
- npc.say() 메서드를 호출하여 NPC의 인사말을 출력합니다.
- npc.say() 메서드:
- "안녕하세요! " + name + "입니다."는 문자열을 생성하는데, 이때 name 변수는 NPC 객체의 이름을 가리킵니다.
- System.out.println()을 사용하여 해당 문자열을 출력합니다.
따라서, 위의 코드는 NPC 클래스를 정의하고, main 메서드에서 NPC 객체를 생성하여 이름과 체력을 설정한 후, NPC의 인사말을 출력하는 간단한 프로그램입니다.
오버로딩(Overloading)
오버로딩(Overloading)은 객체지향 프로그래밍에서 동일한 이름을 가진 메서드 또는 생성자를 여러 개 정의하는 것을 말합니다. 오버로딩을 통해 같은 작업을 수행하지만 다른 매개변수를 받는 경우에도 동일한 메서드 또는 생성자 이름을 사용할 수 있습니다.
오버로딩을 사용하면 다음과 같은 이점이 있습니다:
- 가독성: 비슷한 기능을 가진 메서드들을 동일한 이름으로 그룹화할 수 있어 코드의 가독성을 높여줍니다.
- 일관성: 유사한 작업을 수행하는 메서드들이 동일한 이름을 가지므로, 사용자는 동일한 작업에 대해 일관된 방식으로 메서드를 호출할 수 있습니다.
- 편의성: 다양한 매개변수를 사용하여 메서드를 호출할 수 있기 때문에, 사용자는 다양한 상황에서 편리하게 메서드를 활용할 수 있습니다.
오버로딩의 조건은 다음과 같습니다:
- 메서드 이름이 동일해야 합니다.
- 매개변수의 개수 또는 타입이 달라야 합니다. (매개변수의 순서는 상관없음)
- 메서드의 반환 타입은 오버로딩과 무관합니다.
자바에서는 메서드 오버로딩을 지원하며, 오버로딩된 메서드는 컴파일러가 매개변수의 타입과 개수를 기반으로 적절한 메서드를 호출할 수 있도록 해줍니다. 이를 통해 유연하고 다양한 상황에서 메서드를 사용할 수 있습니다.
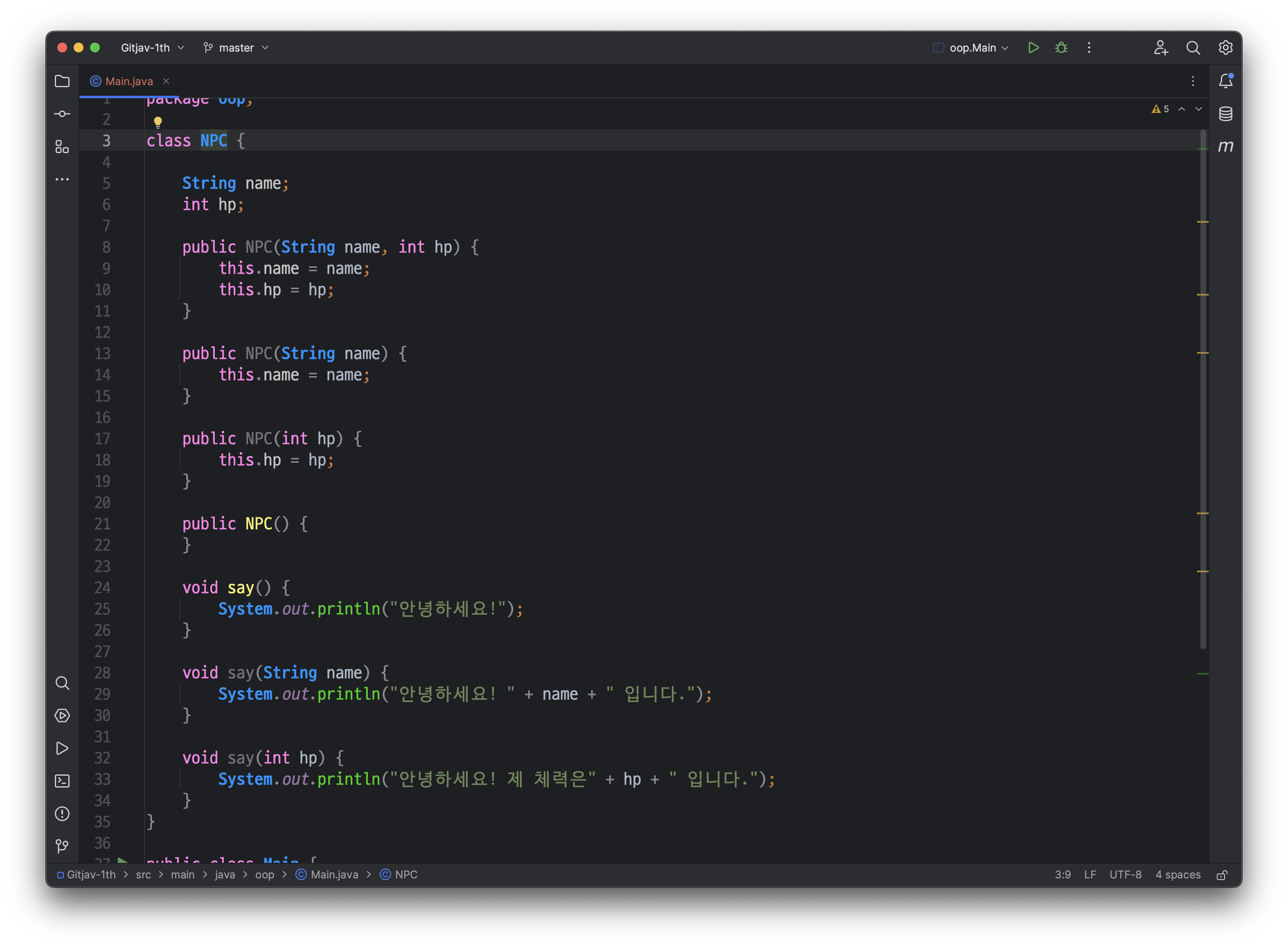
class NPC {
String name;
int hp;
public NPC(String name, int hp) {
this.name = name;
this.hp = hp;
}
public NPC(String name) {
this.name = name;
}
public NPC(int hp) {
this.hp = hp;
}
public NPC() {
}
void say() {
System.out.println("안녕하세요!");
}
void say(String name) {
System.out.println("안녕하세요! " + name + " 입니다.");
}
void say(int hp) {
System.out.println("안녕하세요! 제 체력은" + hp + " 입니다.");
}
}
public class Main {
public static void main(String[] args) {
NPC npc = new NPC();
npc.name = "홍길동";
npc.hp = 100;
npc.say();
}
}
위의 코드는 오버로딩(Overloading) 개념을 활용한 예시입니다. 클래스 NPC에서는 생성자와 메서드를 오버로딩하여 다양한 방식으로 NPC 객체를 초기화하고 동작시킬 수 있습니다.
- 생성자 오버로딩:
- 클래스 NPC는 총 4개의 생성자를 오버로딩하여 다양한 매개변수 조합으로 객체를 초기화할 수 있습니다.
- 첫 번째 생성자 public NPC(String name, int hp)은 name과 hp를 매개변수로 받아서 객체의 name과 hp를 설정합니다.
- 두 번째 생성자 public NPC(String name)은 name만 매개변수로 받아서 객체의 name을 설정합니다.
- 세 번째 생성자 public NPC(int hp)은 hp만 매개변수로 받아서 객체의 hp를 설정합니다.
- 네 번째 생성자 public NPC()는 매개변수를 받지 않으며, 아무 작업도 수행하지 않습니다.
- 메서드 오버로딩:
- NPC 클래스에는 say() 메서드와 say(String name) 메서드, 그리고 say(int hp) 메서드가 오버로딩되어 정의되어 있습니다.
- 첫 번째 say() 메서드는 매개변수를 받지 않고, 단순히 "안녕하세요!"를 출력합니다.
- 두 번째 say(String name) 메서드는 name 매개변수를 받아서 NPC의 이름을 포함한 인사말을 출력합니다.
- 세 번째 say(int hp) 메서드는 hp 매개변수를 받아서 NPC의 체력을 포함한 인사말을 출력합니다.
오버로딩은 같은 이름을 가지면서 매개변수의 타입, 개수, 순서가 다른 여러 개의 메서드를 정의하는 것을 가능하게 합니다. 이를 통해 다양한 상황에서 편리하게 메서드를 사용할 수 있습니다. NPC 클래스의 생성자와 메서드는 각각 다른 매개변수 조합에 대응하여 오버로딩되어 있어 다양한 방식으로 NPC 객체를 초기화하고 동작시킬 수 있습니다.
오버라이드(Override)와 오버로딩(Overloading)은 둘 다 객체지향 프로그래밍에서 메서드와 생성자를 다양하게 활용하기 위한 개념입니다. 공통점과 차이점을 설명해 보겠습니다.
공통점:
- 이름 공유
: 오버라이드와 오버로딩은 모두 동일한 이름을 가진 메서드나 생성자를 다양하게 사용할 수 있게 해 줍니다. - 다형성
: 오버라이드와 오버로딩은 다형성을 구현하는 방식입니다. 동일한 이름을 가진 메서드를 다양한 방식으로 호출하거나 구현함으로써 다형성을 실현할 수 있습니다.
차이점:
- 목적:
- 오버라이드: 상속 관계에서 자식 클래스가 부모 클래스의 메서드를 재정의하여 자신에 맞게 동작을 변경하거나 확장합니다.
- 오버로딩: 동일한 클래스 내에서 메서드를 다양한 매개변수 조합으로 정의하여 다른 호출 방식에 대응할 수 있게 합니다.
- 조건:
- 오버라이드: 부모 클래스의 메서드와 동일한 시그니처를 가져야 하며, 접근 제어자를 변경하거나 예외를 던지는 범위를 조절할 수 있습니다.
- 오버로딩: 메서드 이름은 동일하지만 매개변수의 개수, 타입, 순서가 다른 메서드를 정의합니다.
- 상속 관계:
- 오버라이드: 상속 관계에서만 발생합니다. 자식 클래스에서 부모 클래스의 메서드를 재정의합니다.
- 오버로딩: 같은 클래스 내에서 메서드를 다양하게 정의하는 것으로, 상속과 관련이 없습니다.
요약하면, 오버라이드는 상속 관계에서 동작하며 메서드를 재정의하여 부모 클래스의 동작을 변경하거나 확장합니다. 오버로딩은 같은 클래스 내에서 메서드를 다양하게 정의하여 다른 매개변수 조합에 대응할 수 있도록 합니다. 이러한 개념들을 통해 객체지향 프로그래밍에서 유연하고 다양한 동작을 구현할 수 있습니다.
접근 제한자
자바에서 접근 제한자(Access Modifiers)는 클래스, 인터페이스, 변수, 메서드 등의 멤버에 대한 접근 수준을 제어하는 데 사용됩니다. 접근 제한자를 사용하면 캡슐화와 정보 은닉 원칙에 따라 클래스의 구현 세부 정보를 감추고 외부로부터 보호할 수 있습니다. 자바에서는 주로 네 가지 접근 제한자가 사용됩니다.
private
: private 접근 제한자로 선언된 멤버는 오직 같은 클래스 내에서만 접근할 수 있습니다. 이를 통해 클래스의 내부 구현을 외부로부터 보호하고, 클래스 내부에서만 사용되는 변수나 메서드를 숨길 수 있습니다.
class MyClass {
private int privateVar; // 같은 클래스 내에서만 접근 가능
private void privateMethod() {
// 같은 클래스 내에서만 접근 가능
}
}
default
: 접근 제한자를 명시하지 않으면 기본적으로 'default' 접근 제한자가 적용됩니다. 'default' 접근 제한자로 선언된 멤버는 같은 패키지 내의 클래스에서 접근할 수 있습니다. 이를 통해 패키지 내에서 공유되어야 하는 멤버를 구현할 수 있습니다.
class MyClass {
int defaultVar; // 같은 패키지 내에서 접근 가능
void defaultMethod() {
// 같은 패키지 내에서 접근 가능
}
}
protected
: protected 접근 제한자로 선언된 멤버는 같은 패키지 내의 클래스와 해당 클래스를 상속받은 다른 패키지의 하위 클래스에서 접근할 수 있습니다. 이를 통해 상속 관계의 하위 클래스에서 오버라이딩이 필요한 멤버를 구현할 수 있습니다.
class MyClass {
protected int protectedVar; // 같은 패키지 내와 상속받은 다른 패키지의 하위 클래스에서 접근 가능
protected void protectedMethod() {
// 같은 패키지 내와 상속받은 다른 패키지의 하위 클래스에서 접근 가능
}
}
public
: public 접근 제한자로 선언된 멤버는 어디에서나 접근할 수 있습니다. 이를 통해 외부에서 사용할 수 있는 클래스의 API를 정의할 수 있습니다.
class MyClass {
public int publicVar; // 어디에서나 접근 가능
public void publicMethod() {
// 어디에서나 접근 가능
}
}
이러한 접근 제한자들을 사용하여 클래스와 인터페이스의 멤버에 대한 적절한 접근 수준을 지정함으로써, 객체 지향 프로그래밍의 원칙에 따라 캡슐화와 정보 은닉을 구현할 수 있습니다. 이를 통해 클래스의 내부 구현을 보호하고 코드의 유지 보수성을 높일 수 있습니다.
- 클래스의 내부 상태를 나타내는 변수는 외부로부터 직접적인 접근을 제한하고, 대신 getter와 setter 메서드를 사용하여 접근하도록 하세요. 이 경우, 변수는 private 으로 선언하고, getter 와 setter 메서드는 public 또는 protected 로 선언하는 것이 좋습니다.
- 클래스의 내부 구현에만 사용되는 메서드는 private 으로 선언하세요. 이를 통해 클래스의 내부 동작을 외부로부터 숨길 수 있습니다.
- 상속 관계에서 공통적으로 사용되거나 오버라이딩이 필요한 메서드는 protected 로 선언하세요. 이렇게 하면 하위 클래스에서 해당 메서드에 접근할 수 있게 됩니다.
- 외부에서 사용할 수 있는 클래스의 API는 public 으로 선언하세요. 이렇게 하면 다른 클래스나 패키지에서 해당 멤버를 자유롭게 사용할 수 있습니다.
이런 원칙을 따르면서 접근 제한자를 사용하면, 클래스와 인터페이스의 설계를 더욱 견고하게 할 수 있으며 코드의 유지 보수와 확장성을 향상시킬 수 있습니다.
추상 클래스(Abstract Class)
- 추상 클래스는 abstract 키워드를 사용하여 선언됩니다.
- 추상 클래스는 추상 메서드와 일반 메서드를 모두 포함할 수 있습니다.
- 추상 클래스는 상속을 통해 기능을 확장하고 하위 클래스에서 추상 메서드를 구현합니다.
- 하위 클래스는 extends 키워드를 사용하여 추상 클래스를 상속받습니다.
예시 코드:
abstract class Animal {
abstract void makeSound(); // 추상 메소드
void sleep() { // 일반 메소드
System.out.println("The animal is sleeping.");
}
}
class Dog extends Animal {
@Override
void makeSound() {
System.out.println("The dog barks.");
}
}
인터페이스(Interface)
- 인터페이스는 interface 키워드를 사용하여 선언됩니다.
- 인터페이스는 모든 메서드가 추상 메서드이며, Java 8부터는 디폴트 메서드와 정적 메서드를 포함할 수 있습니다.
- 인터페이스는 다중 상속을 허용합니다. 즉, 하나의 클래스는 여러 인터페이스를 구현할 수 있습니다.
- 클래스는 implements 키워드를 사용하여 인터페이스를 구현합니다.
예시 코드:
interface Flyable {
void fly(); // 추상 메소드
}
interface Runnable {
void run(); // 추상 메소드
}
class Bird implements Flyable, Runnable {
@Override
public void fly() {
System.out.println("The bird is flying.");
}
@Override
public void run() {
System.out.println("The bird is running.");
}
}
추상 클래스와 인터페이스를 사용하면 추상화, 캡슐화, 상속 및 다형성과 같은 객체 지향 프로그래밍의 원칙을 구현할 수 있으며, 유연하고 확장 가능한 코드 설계를 가능하게 합니다.
객체지향 프로그래밍(OOP) 기초
// 추상 클래스
abstract class Shape {
// 추상 메소드
abstract double getArea();
// 일반 메소드
protected void printInfo() {
System.out.println("This is a shape.");
}
}
// 인터페이스
interface Colorable {
void setColor(String color);
String getColor();
}
// 상속 및 인터페이스 구현
class Rectangle extends Shape implements Colorable {
private double width;
private double height;
private String color;
// 생성자 오버로딩
public Rectangle(double width, double height) {
this.width = width;
this.height = height;
}
public Rectangle(double width, double height, String color) {
this.width = width;
this.height = height;
this.color = color;
}
// 추상 메소드 구현
@Override
public double getArea() {
return width * height;
}
// 인터페이스 메소드 구현
@Override
public void setColor(String color) {
this.color = color;
}
@Override
public String getColor() {
return color;
}
}
public class Main {
public static void main(String[] args) {
Rectangle rect = new Rectangle(10, 5, "blue");
System.out.println("Area: " + rect.getArea());
System.out.println("Color: " + rect.getColor());
rect.printInfo();
}
}
주어진 코드는 추상 클래스와 인터페이스, 그리고 클래스의 상속과 인터페이스 구현을 보여주는 예시입니다. 코드를 상세히 설명하겠습니다.
- Shape 클래스:
- Shape 클래스는 추상 클래스로 선언되었습니다. 추상 클래스는 abstract 키워드로 선언되며, 일부 메서드는 구현되지 않고 선언만 되어 있습니다.
- getArea()라는 추상 메서드가 선언되어 있습니다. 이 메서드는 도형의 면적을 반환하는 역할을 하며, 하위 클래스에서 구현해야 합니다.
- printInfo()라는 일반 메서드가 선언되어 있습니다. 이 메서드는 도형에 대한 정보를 출력하는 역할을 합니다.
- Colorable 인터페이스:
- Colorable 인터페이스는 setColor()와 getColor()라는 두 개의 메서드를 선언합니다. 이 인터페이스를 구현하는 클래스는 이 메서드들을 반드시 구현해야 합니다.
- Rectangle 클래스:
- Rectangle 클래스는 Shape 클래스를 상속하고, Colorable 인터페이스를 구현하는 클래스입니다.
- width와 height라는 두 개의 멤버 변수와 color라는 멤버 변수가 선언되어 있습니다.
- 생성자 오버로딩을 통해 width와 height를 받는 생성자와 width, height, color를 받는 생성자가 정의되어 있습니다.
- getArea() 메서드는 Shape 클래스의 추상 메서드를 구현하여 사각형의 면적을 계산하여 반환합니다.
- setColor()와 getColor() 메서드는 Colorable 인터페이스의 메서드를 구현하여 사각형의 색을 설정하고 반환합니다.
위의 코드는 추상 클래스와 인터페이스의 개념을 보여주는 예시입니다. 추상 클래스는 상속을 통해 하위 클래스에서 구체적인 구현을 할 수 있고, 인터페이스는 클래스가 특정한 기능을 구현하도록 강제하는 역할을 합니다. 이를 통해 코드의 유연성과 재사용성을 높일 수 있습니다.
JVM 메모리 모델

JVM(Java Virtual Machine) 메모리 모델은 크게 5개 영역으로 나뉩니다: 메소드 영역, 힙 영역, 스택 영역, 네이티브 메소드 스택 영역, PC 레지스터 영역.
메소드 영역 (Method Area)
메서드 영역은 클래스 정보, 상수 풀, 필드와 메소드 데이터, 메서드와 생성자의 바이트 코드, 런타임 상수 풀 등이 저장됩니다. 이 영역은 모든 스레드에 공유되며, 자바 가상 머신이 시작할 때 생성됩니다.
힙 영역 (Heap Area)
힙 영역은 객체와 객체에 대한 메모리를 할당하는 곳입니다. 이 영역은 가비지 컬렉터에 의해 관리되며, 메모리 부족 시 OutOfMemoryError를 발생시킵니다. 힙 영역은 메소드 영역과 마찬가지로 모든 스레드에 공유됩니다.
예시 코드:
public class Student {
String name;
int age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
}
public class Main {
public static void main(String[] args) {
Student student = new Student("John", 25);
}
}위 코드에서 new Student("John", 25);를 실행하면, 객체의 메모리가 힙 영역에 할당됩니다.
스택 영역 (Stack Area)
스택 영역은 메소드 호출과 로컬 변수에 대한 메모리를 할당하는 곳입니다. 각 스레드는 자신만의 스택 영역을 가지며, 메소드 호출 시 프레임이 스택에 생성되고 메소드 실행이 완료되면 프레임이 스택에서 제거됩니다. 스택 오버플로우가 발생할 경우 StackOverflowError가 발생합니다.
예시 코드:
public class Main {
public static void main(String[] args) {
int localVar1 = 10;
int localVar2 = 20;
int sum = add(localVar1, localVar2);
}
public static int add(int num1, int num2) {
return num1 + num2;
}
}위 코드에서 main 메서드와 add 메소드가 호출될 때, 스택 영역에 프레임이 생성되며, 각 프레임에 로컬 변수가 저장됩니다.
결론적으로, JVM 메모리 모델은 메소드 영역, 힙 영역, 스택 영역으로 구성되어 있습니다. 이러한 구조를 이해하면 자바 프로그램의 메모리 사용과 관련된 이슈를 더 잘 이해하고, 성능 최적화와 디버깅에 도움이 됩니다.
전체 요약:
class Dog {
// 메소드 영역: 클래스 정보, 필드와 메소드 데이터 등이 저장됩니다.
private String name;
public Dog(String name) {
this.name = name;
}
public void bark() {
System.out.println(name + " says: Woof!");
}
}
public class Main {
public static void main(String[] args) {
// 스택 영역: 메소드 호출과 로컬 변수에 대한 메모리를 할당하는 곳입니다.
String dogName = "Buddy";
// 힙 영역: 객체와 객체에 대한 메모리를 할당하는 곳입니다.
Dog myDog = new Dog(dogName);
// 메소드 호출 시 스택에 프레임이 생성됩니다.
myDog.bark();
}
}위 코드에서는 JVM 메모리 영역 중 메서드 영역, 스택 영역, 힙 영역에 대한 예시를 보여주고 있습니다. Dog 클래스의 정보, 필드, 메소드 데이터는 메소드 영역에 저장되며, main 메소드의 로컬 변수인 dogName은 스택 영역에 저장됩니다. 힙 영역에는 Dog 객체가 할당되어 있습니다. 메소드 호출 시 스택에 프레임이 생성되며 메서드가 종료되면 프레임이 제거됩니다.
Git 원리
Git은 버전 관리 시스템(VCS, Version Control System) 중 하나로, 소스 코드와 파일의 변경 내역을 효과적으로 관리하는 도구입니다. Git은 개발자들이 협업하고 코드를 추적하며 변경사항을 관리하는 데에 많이 사용됩니다.

Git 초기화
git init은 Git 저장소를 초기화하는 명령어입니다. 이 명령어를 사용하면 현재 디렉터리를 Git 저장소로 설정하고, Git이 버전 관리를 시작할 수 있는 상태로 만듭니다. 아래는 git init의 주요 특징과 동작에 대한 설명입니다:
- Git 저장소 초기화
- git init 명령어는 현재 디렉토리를 Git 저장소로 설정합니다.
- 이 명령어를 실행하면. git이라는 숨김 폴더가 생성되며, 이 폴더에 Git 저장소에 필요한 모든 정보와 메타데이터가 저장됩니다.
- 버전 관리 시작
- git init 명령어를 실행하면 Git은 현재 디렉터리의 파일을 추적하고 변경 사항을 관리하기 시작합니다.
- Git은 파일의 변경 내용을 스냅샷으로 캡처하고, 변경 내역을 커밋(commit) 단위로 저장합니다.
- 이를 통해 코드의 버전을 관리하고 변경 이력을 추적할 수 있습니다.
- .git 폴더
- git init 명령어 실행 시 생성되는 .git 폴더는 Git 저장소의 핵심이 위치한 폴더입니다.
- .git 폴더에는 객체 저장소(object store), 인덱스(index), 로그(commit log), 설정 파일(config) 등 Git의 동작에 필요한 정보가 포함됩니다.
- .git 폴더는 일반적으로 숨김 폴더로 표시되어 보이지 않습니다.
- 새로운 Git 저장소
- git init 명령어를 사용하여 기존에 생성된 Git 저장소가 아닌 새로운 Git 저장소를 만들 수 있습니다.
- 새로운 Git 저장소를 초기화하면 이전에 버전 관리가 되지 않았던 파일들을 Git이 추적하고 변경 이력을 기록할 수 있게 됩니다.
git init 명령어를 사용하여 Git 저장소를 초기화하면 버전 관리를 시작할 수 있으며, 이후로 변경된 파일의 추적과 커밋을 통해 변경 이력을 관리할 수 있게 됩니다. 이는 Git의 기본적인 동작을 활성화하고, 프로젝트의 버전을 체계적으로 관리하기 위한 시작점이 됩니다.
Git 작업트리
깃(Git) 작업 트리(Working Tree)는 현재 로컬 저장소의 파일과 디렉터리들이 있는 공간으로, 사용자가 실제로 작업하는 영역입니다. 작업 트리는 Git의 세 가지 주요 구성 요소 중 하나로, 다른 두 요소는 인덱스(Index)와 헤드(HEAD)입니다.
작업 트리에서는 개발자가 파일을 수정, 추가, 삭제하는 등의 작업을 수행하며, 변경 사항을 Git으로 관리할 수 있습니다. 작업 트리의 변경 사항을 저장소에 반영하려면, 다음 단계를 거칩니다.

변경 사항을 인덱스에 추가(Staging)
: git add 명령어를 사용해 변경된 파일들을 인덱스에 추가합니다. 인덱스는 작업 트리와 로컬 저장소 사이의 중간 단계로 작용합니다.
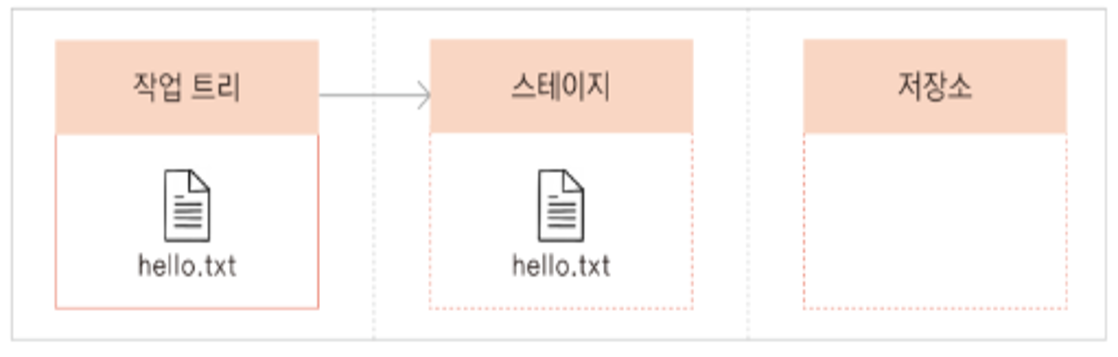
인덱스의 변경 사항을 로컬 저장소에 커밋(Commit)
: git commit 명령어를 사용해 인덱스에 있는 변경 사항을 로컬 저장소에 반영하고, 새로운 커밋을 생성합니다.
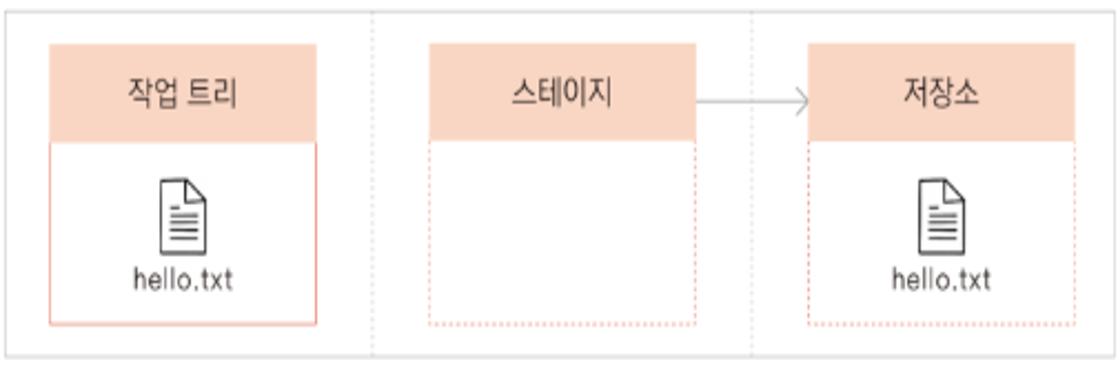
작업 트리는 소스 코드와 관련된 모든 변경 사항을 추적하며, 개발자가 실제로 작업하는 환경입니다. 이를 통해 개발자는 변경 사항을 쉽게 관리하고, 이전 버전으로 롤백하거나, 다른 브랜치와 병합하는 등의 작업을 수행할 수 있습니다.
Git 파일 상태 및 라이프사이클
Git의 라이프 사이클은 파일의 상태를 관리하는 데 도움이 되는 여러 단계를 포함하고 있습니다. 파일은 크게 Untracked, Tracked, Unmodified, Modified, Staged의 5가지 상태로 나뉩니다. 아래에서 각 상태와 전환 과정에 대해 설명하겠습니다.
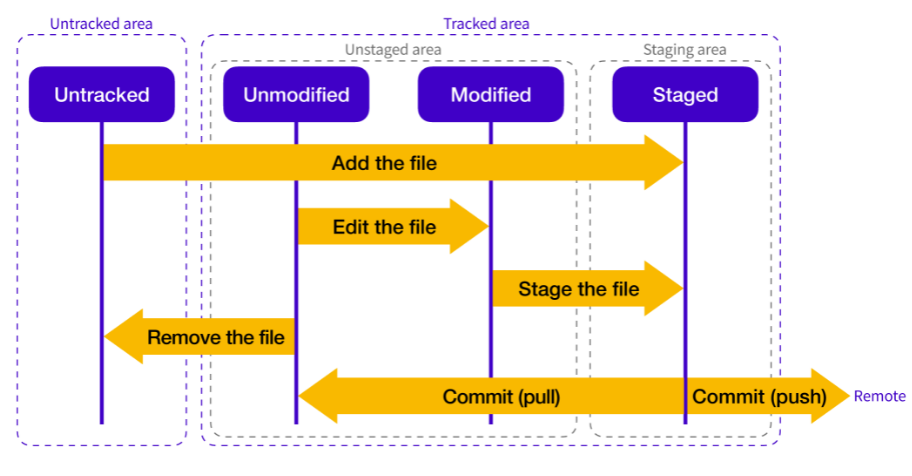
- Untracked
: 깃이 아직 관리하지 않는 파일 상태입니다. 새로 생성된 파일이나 .gitignore에 명시된 파일들이 여기에 해당됩니다. - Tracked
: 깃이 관리하는 파일로, 이전 커밋에 포함되어 있습니다. Tracked 상태의 파일은 다시 세 가지 상태(Unmodified, Modified, Staged)로 나뉩니다.b. Modified: 마지막 커밋 이후 변경된 파일 상태입니다. 변경 사항이 아직 Staging Area에 추가되지 않았습니다.- c. Staged: 변경된 파일이 Staging Area에 추가된 상태입니다. 다음 커밋에 포함되기 위해 대기 중입니다.
- a. Unmodified: 마지막 커밋 이후 변경되지 않은 파일 상태입니다.
라이프 사이클의 주요 전환 단계:
- Staging ( Working Tree -> Staging Area )
: git add <file> 명령어를 사용하여 변경된 파일을 Staging Area에 추가합니다. 파일 상태는 Modified에서 Staged로 전환됩니다. - Committing ( Staging Area -> Git Repository )
: git commit 명령어를 사용하여 Staging Area에 있는 변경 사항을 Git Repository에 저장하고, 새로운 커밋을 생성합니다. 파일 상태는 Staged에서 Unmodified로 전환됩니다. - Modifying ( Working Tree -> 직접 변경 )
: 소스 코드를 수정하면 파일 상태가 Unmodified에서 Modified로 전환됩니다. - Untracking ( Tracked -> Untracked )
: 파일을 삭제하거나 .gitignore에 추가하면, 파일 상태는 Tracked에서 Untracked로 전환됩니다.
이러한 라이프 사이클을 통해 깃은 소스 코드의 변경 사항을 추적하고 관리할 수 있으며, 협업과 이력 관리를 효율적으로 수행할 수 있습니다.
GitJav 멘토링 3차 오프라인 활동사진














사진을 불펌하거나 무단도용을 금합니다!!!

여러분의 지적과 피드백은 매우 소중합니다! 만약 제 코드나 설명에 대해
어떤 문제점이나 개선 사항이 있다면 언제든지 댓글로 남겨주세요. 감사합니다:)
'🏄🏻♂️ : activity' 카테고리의 다른 글
| [ SSAFY ] - 싸피 10기 전공자 합격 후기 - 지원부터 최종합격까지 ! (2) | 2023.07.08 |
|---|---|
| GitJav 멘토링: 객체지향 프로그래밍 연습과 Git 라이프사이클 ep.5 (1) | 2023.05.24 |
| GitJav 멘토링: JAVA 배열, 클래스, 객체, 인터페이스, 상속 ep.3 (0) | 2023.05.03 |
| GitJav 멘토링: 자바 프로젝트 생성 및 구조, 조건문과 반복문 ep.2 (0) | 2023.04.19 |
| GitJav 멘토링: 자바의 변수와 자료형, 연산자 ep.1 (0) | 2023.04.12 |