

지난주에는 학교 시험기간인 관계로 한 주 건너뛰고 이번 주부터 다시 멘토링을 재개하게 되었습니다. 이번 시간에는 지금까지 배운 내용들을 짧게 점검을 해보고 생각보다 시간이 많지 않은 관계로 빠르게 진도를 나가도록 하겠습니다:)

✅ 미니테스트 Check
1. 변수와 상수
변수와 상수는 프로그래밍에서 중요한 개념입니다. 변수는 값을 저장하는 메모리 공간에 이름을 붙인 것으로, 상황에 따라 값이 변경될 수 있습니다. 상수는 값이 변하지 않는 값을 의미합니다.
- 변수는 값을 저장하는 메모리 공간에 이름을 붙인 것입니다. 값이 언제든 변경될 수 있습니다.
- 상수는 값이 변하지 않는 값을 의미합니다.

변수와 상수를 사용할 때는 상황에 맞게 사용해야 합니다. 변수는 값을 반복해서 사용하거나 값을 변경할 때 사용하며, 상수는 값을 변경하지 않고 일정한 값을 사용할 때 사용합니다.
2. 컴파일러와 인터프리터
컴파일러(Compiler)와 인터프리터(Interpreter)는 프로그래밍 언어를 기계어로 변환하는 역할을 합니다. 하지만 두 가지 방식은 서로 다른 방식으로 동작합니다.
- 컴파일러(Compiler)는 소스코드를 기계어로 변환하는 번역기입니다. 소스코드를 전체적으로 분석한 후에 기계어로 변환하여 실행 파일을 생성합니다. 컴파일러는 소스코드를 한 번만 분석하면 되기 때문에 실행 속도가 빠르며, 실행 파일을 생성하므로 실행 시에는 번역 과정이 필요하지 않습니다. 또한, 실행 파일이 생성되므로 다른 기계에서도 실행이 가능합니다. 하지만 소스코드를 번역하는 시간이 오래 걸리고, 오류를 발견하더라도 실행 파일을 생성할 때까지 오류를 찾을 수 없습니다. 또한, 실행 파일을 생성하므로 소스코드를 공개하지 않고 실행 파일만 배포할 수 있습니다.
- 인터프리터(Interpreter)는 소스코드를 한 줄씩 읽어 들여 바로 실행합니다. 소스코드를 실행하기 위해 매번 번역 과정이 필요하기 때문에 실행 속도가 느리지만, 오류를 발견하기 쉽습니다. 소스코드를 한 줄씩 읽어 들이기 때문에 실행하는 도중에 바로 수정이 가능합니다. 또한, 소스코드를 실행하기 때문에 소스코드를 공개해야 합니다.
둘 중 어떤 방식을 사용할지는 상황에 따라 다릅니다. 컴파일러를 사용하면 실행 속도는 빠르지만, 번역하는데 오래 걸리고 오류를 발견하기 어렵습니다. 인터프리터를 사용하면 실행 속도는 느리지만, 바로 수정이 가능하고 오류를 발견하기 쉽습니다.
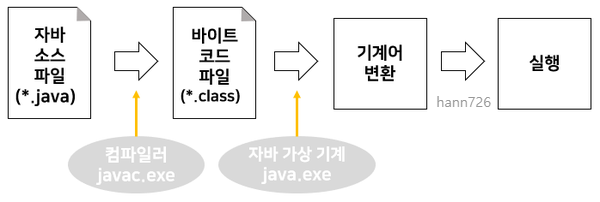
참고로, 일부 프로그래밍 언어는 컴파일러와 인터프리터를 모두 사용합니다. 예를 들어, 자바(Java)는 소스코드를 컴파일하여 바이트코드(기계어와 유사한 중간 단계)를 생성한 후에, 인터프리터를 사용하여 바이트코드를 기계어로 변환합니다. 이렇게 함으로써 컴파일러의 장점과 인터프리터의 장점을 모두 활용할 수 있습니다.
3. 클래스와 객체
클래스(Class)와 객체(Object)는 객체지향 프로그래밍의 핵심 개념입니다. 자바(Java)는 객체지향 프로그래밍 언어이므로, 클래스와 객체에 대한 이해가 필수적입니다.
- 클래스(Class)는 객체를 정의하는 틀(Template)입니다. 클래스는 객체의 속성(변수)과 동작(메서드)을 정의합니다. 클래스는 객체를 생성하기 위한 설계도와 같은 역할을 합니다. 클래스는 다음과 같은 구문을 사용하여 선언합니다.
public class MyClass {
// 변수와 메서드를 정의합니다.
}위의 예제에서 MyClass는 클래스의 이름이며, public 키워드는 클래스가 다른 클래스에서 접근 가능하다는 것을 의미합니다.
- 객체(Object)는 클래스를 기반으로 생성된 실체입니다. 객체는 클래스의 인스턴스(Instance)라고도 합니다. 객체는 클래스에서 정의한 속성(변수)과 동작(메서드)을 가지며, 각 객체는 서로 다른 값을 가질 수 있습니다. 객체는 다음과 같은 구문을 사용하여 생성합니다.
MyClass myObject = new MyClass();위의 예제에서 MyClass는 클래스의 이름이며, myObject는 객체의 이름입니다. new 키워드는 객체를 생성하는 키워드이며, MyClass()는 클래스의 생성자(Constructor)입니다.
클래스와 객체를 사용하는 이유는 다음과 같습니다.
- 코드를 재사용하기 쉽습니다. 클래스를 한 번 정의하면 여러 개의 객체를 생성하여 사용할 수 있기 때문입니다.
- 코드의 가독성이 높아집니다. 클래스를 사용하면 관련된 속성과 동작을 한 곳에 모아둘 수 있기 때문입니다.
- 유지보수가 쉬워집니다. 클래스를 사용하면 수정이 필요한 경우 해당 클래스만 수정하면 되기 때문입니다.
4. 메서드
메서드(Method)는 객체가 수행하는 동작(기능)을 정의하는 코드 블록입니다. 자바(Java)에서는 메서드를 클래스(Class) 내부에 정의하여 사용합니다. 메서드는 다음과 같은 형태로 선언합니다.
[접근제어자] [반환형] [메서드이름](매개변수) {
// 메서드의 기능을 구현합니다.
}위의 구문에서, 접근제어자는 메서드에 접근할 수 있는 범위를 지정합니다. 반환형은 메서드가 실행된 후에 반환하는 값의 자료형을 지정합니다. 메서드이름은 메서드를 호출할 때 사용하는 이름입니다. 매개변수는 메서드 실행 시에 전달되는 값입니다.
메서드를 사용하는 이유는 다음과 같습니다.
- 코드의 재사용성이 높아집니다. 메서드를 정의해 두면 여러 곳에서 호출하여 사용할 수 있기 때문입니다.
- 코드의 가독성이 높아집니다. 메서드를 사용하면 코드를 논리적으로 분리할 수 있기 때문입니다.
- 코드의 유지보수성이 높아집니다. 메서드를 사용하면 메서드 내부의 코드만 수정하면 되므로, 전체 코드를 수정할 필요가 없습니다.
메서드를 사용하는 방법은 다음과 같습니다.
- 메서드는 클래스 내부에 정의합니다.
- 메서드 이름은 의미 있는 이름으로 지정합니다.
- 메서드의 매개변수는 필요한 경우에만 사용합니다.
- 메서드의 반환형은 메서드가 실행된 후에 반환하는 값의 자료형으로 지정합니다. 반환형이 없는 경우에는 void를 사용합니다.
메서드는 객체지향 프로그래밍에서 가장 기본적인 개념 중 하나이며, 자바뿐만 아니라 다른 객체지향 프로그래밍 언어에서도 동일한 개념으로 사용됩니다.
5. 메모리
"메모리(memory)"란 컴퓨터에서 프로그램이 실행되는 공간을 의미합니다. 메모리는 컴퓨터의 주 기억장치로, 프로그램이 실행되는 동안 필요한 데이터와 명령어를 저장합니다.
메모리는 물리적으로는 RAM(Random Access Memory) 칩으로 구성되어 있으며, CPU(Central Processing Unit)가 데이터를 읽고 쓸 수 있는 공간입니다.

프로그래밍에서 메모리는 변수, 배열, 객체 등의 데이터를 저장하기 위한 공간으로 사용됩니다. 프로그램이 실행되면 메모리는 운영체제(OS)에 의해 프로그램을 위한 메모리 영역이 할당되며, 프로그램이 종료되면 메모리 영역은 운영체제에 반환됩니다. 메모리는 다음과 같은 구조로 이루어져 있습니다.
- 코드(Code) 영역
: 프로그램의 코드가 저장되는 영역입니다. 실행 파일이 메모리에 로드될 때 코드 영역에 저장됩니다. - 데이터(Data) 영역
: 전역 변수(Global Variable)와 정적 변수(Static Variable)가 저장되는 영역입니다. 프로그램의 시작과 함께 할당되며, 종료될 때까지 유지됩니다. - 스택(Stack) 영역
: 함수 호출 시에 사용되는 지역 변수(Local Variable)와 매개변수(Parameter)가 저장되는 영역입니다. 함수 호출 시에 메모리가 할당되며, 함수가 반환될 때 메모리가 반환됩니다. - 힙(Heap) 영역
: 동적으로 할당된 메모리가 저장되는 영역입니다. 프로그램이 실행되는 동안 메모리를 동적으로 할당하고 해제할 때 사용됩니다.
메모리는 프로그램을 실행하는 데 매우 중요한 역할을 합니다. 메모리 공간이 부족하면 프로그램이 오류를 발생시키거나 강제 종료될 수 있습니다. 따라서 프로그래밍을 할 때는 메모리 사용에 대한 고려가 필요합니다. 메모리 누수(Memory Leak)나 너무 많은 메모리 사용 등의 문제가 발생하지 않도록 프로그래밍을 해야 합니다.
6. 기본자료형과 참조자료형
자바(Java)에서 기본자료형(Primitive Data Type)은 정수, 실수, 문자, 논리값 등의 단순한 값을 저장하는 자료형을 말합니다. 기본자료형은 미리 정의된 자료형으로, 자바에서 제공하는 8가지 기본자료형이 있습니다.
정수형
- byte
: 1바이트(8비트) 크기의 정수 자료형입니다. -128 ~ 127 범위의 값을 저장할 수 있습니다. - short
: 2바이트(16비트) 크기의 정수 자료형입니다. -32,768 ~ 32,767 범위의 값을 저장할 수 있습니다. - int
: 4바이트(32비트) 크기의 정수 자료형입니다. -2,147,483,648 ~ 2,147,483,647 범위의 값을 저장할 수 있습니다. - long
: 8바이트(64비트) 크기의 정수 자료형입니다. -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807 범위의 값을 저장할 수 있습니다.
실수형
- float
: 4바이트(32비트) 크기의 실수 자료형입니다. 대략 6~7자리의 정밀도를 가지며, 소수점 이하 7자리까지 저장할 수 있습니다. - double
: 8바이트(64비트) 크기의 실수 자료형입니다. 대략 15자리의 정밀도를 가지며, 소수점 이하 15자리까지 저장할 수 있습니다.
문자형
- char
: 2바이트(16비트) 크기의 문자 자료형입니다. 유니코드(Unicode) 문자를 저장할 수 있습니다.
논리형
- boolean
: true 또는 false 값을 저장하는 자료형입니다.
참조자료형(Reference Data Type)은 객체(Object)의 주소를 저장하는 자료형을 말합니다. 참조자료형은 클래스(Class), 인터페이스(Interface), 배열(Array) 등이 있습니다. 참조자료형은 객체를 생성하고 사용할 때 사용됩니다. 예를 들어 다음과 같이 객체를 생성하고 사용할 수 있습니다.
String str = new String("Hello World!"); // String 클래스의 인스턴스 생성
int[] arr = new int[5]; // int 배열 생성
위의 예제에서, String은 참조자료형이며, str은 String 클래스의 인스턴스입니다. 또한, int[]는 참조자료형이며, arr은 int 배열입니다.
기본자료형과 참조자료형은 메모리 사용 방식이 다릅니다. 기본자료형은 스택(Stack) 영역에 값을 직접 저장합니다. 반면에 참조자료형은 스택(Stack) 영역에 객체의 주소를 저장하고, 실제 객체는 힙(Heap) 영역에 저장합니다. 따라서 참조자료형을 사용할 때는 객체의 생성과 소멸에 대한 고려가 필요합니다.
String hello1 = new String("Hello");
String hello2 = new String("Hello");
if (hello1 == hello2) System.out.println("Hello")위 코드는 두 개의 String 객체를 생성하고, 두 객체의 주소를 비교하여 결과를 출력하는 코드입니다.
- 먼저, String 클래스는 참조자료형(Reference Data Type)입니다. 따라서 String 객체를 생성할 때는 new 연산자를 사용하여 Heap 영역에 객체를 생성합니다.
- 위 코드에서는 "Hello"라는 문자열을 가진 두 개의 String 객체를 생성합니다. 두 객체는 서로 다른 주소를 가지게 됩니다.
- if문에서는 두 객체의 주소를 비교하여 같은 객체인지를 판단합니다. 하지만, 두 객체는 서로 다른 객체이므로 주소가 다릅니다.
만약 두 개의 String 객체를 내용을 비교하고 싶다면, equals() 메서드를 사용해야 합니다. equals() 메서드는 객체의 내용을 비교하여 동등성을 판단합니다. 따라서 아래와 같이 코드를 수정해야 합니다.
String hello1 = new String("Hello");
String hello2 = new String("Hello");
if (hello1.equals(hello2)) {
System.out.println("Hello");
}이렇게 수정하면 hello1과 hello2의 내용이 동일하므로 "Hello"가 출력됩니다.
7. 삼항 연산자
int a = 5;
int b.= 3;
int result = a > b ? a : b ;
System.out.println(result);위 코드는 삼항 연산자(Ternary Operator)를 사용하여 두 개의 변수 a와 b를 비교하고, 더 큰 값을 result 변수에 저장한 후 출력하는 코드입니다.
- 먼저, 변수 a에 5를, 변수 b에 3을 대입합니다.
- 삼항 연산자는 조건식 ? 값1 : 값2 형태로 사용됩니다. 조건식이 true이면 값1이, false이면 값2가 선택됩니다. 따라서 위 코드에서는 a > b인지를 조건식으로 사용합니다.
- 조건식 a > b가 true이면 삼항 연산자는 a 값을 선택하고, false이면 b 값을 선택합니다. 따라서 위 코드에서는 a 값인 5가 result 변수에 저장됩니다.
- 마지막으로, System.out.println() 메서드를 사용하여 result 변수의 값을 출력합니다.
따라서 위 코드를 실행하면 5가 출력됩니다.
8. 증감 연산자
증감 연산자는 변수의 값을 1 증가시키거나 감소시키는 연산자입니다. 증감 연산자는 전위(prefix) 연산자와 후위(postfix) 연산자로 나뉩니다.
- 전위(prefix) 증감 연산자는 변수의 값을 1 증가시키거나 감소시킨 후, 증가된 값을 반환합니다.
예를 들어, ++i는 i 변수의 값을 1 증가시킨 후, 증가된 값을 반환합니다. - 후위(postfix) 증감 연산자는 변수의 값을 1 증가시키거나 감소시키기 전, 변수의 값을 반환합니다.
예를 들어, i++는 i 변수의 값을 반환한 후, i 변수의 값을 1 증가시킵니다.
증감 연산자는 변수의 값을 1 증가시키거나 감소시키는 간단한 연산을 수행하기 때문에 코드의 간결성을 높일 수 있습니다. 하지만, 증감 연산자를 남발하면 코드의 가독성을 해치고, 실수를 유발할 가능성이 있습니다. 또한, 증감 연산자를 사용할 때는 전위(prefix) 연산자와 후위(postfix) 연산자의 차이를 이해하고 사용해야 합니다.
int num = 10;
num++;
System.out.println(++num);코드의 실행 순서는 다음과 같습니다:
- num 변수에 10이 할당됩니다.
- num++은 현재 num의 값을 사용한 후에 1을 증가시킵니다. 따라서 이 시점에서 num의 값은 11이 됩니다.
- ++num은 num의 값을 1 증가시킨 후에 사용합니다. 따라서 이 시점에서 num의 값은 12가 됩니다.
- System.out.println()은 num의 현재 값을 출력합니다. 따라서 출력 결과는 12가 됩니다.
9. 형변환
형변환이란 하나의 데이터 타입에서 다른 데이터 타입으로 변환하는 것을 말합니다. 자바에서는 기본형(primitive type)과 참조형(reference type) 간의 형변환이 가능합니다.
형변환은 크게 두 가지로 나눌 수 있습니다.
- Widening Casting: 작은 크기의 데이터 타입에서 큰 크기의 데이터 타입으로 자동으로 형변환됩니다. 예를 들어, int 타입 변수의 값을 double 타입 변수에 대입할 때, int 타입이 double 타입보다 작기 때문에 자동으로 형변환이 이루어집니다.
- Narrowing Casting: 큰 크기의 데이터 타입에서 작은 크기의 데이터 타입으로 형변환됩니다. 이는 명시적으로 형변환을 수행해야 합니다. 예를 들어, double 타입 변수의 값을 int 타입 변수에 대입할 때, double 타입이 int 타입보다 크기 때문에 명시적으로 형변환을 수행해야 합니다.
int a = 10;
double b = a;
System.out.println(b);위 코드는 int 타입 변수 a를 선언하고 10을 대입한 후, double 타입 변수 b에 a를 대입한 후, b를 출력하는 코드입니다.
- 먼저, int 타입 변수 a를 선언하고 10을 대입합니다.
- 그다음, double 타입 변수 b를 선언하고 a를 대입합니다. 이때, int 타입 변수 a가 double 타입 변수 b보다 작은 자료형이므로, 자동으로 형변환(widening primitive conversion)이 발생합니다. 즉, int 타입 변수 a는 double 타입으로 변환되어 double 타입 변수 b에 대입됩니다.
- 마지막으로, System.out.println() 메서드를 사용하여 double 타입 변수 b의 값을 출력합니다.
따라서 위 코드를 실행하면 10.0이 출력됩니다.
2주 차 - 별 문자 피라미드 그리기
public class Main {
public static void main(String[] args) {
int n = 5; // 삼각형의 높이
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= i; j++) {
System.out.print("*");
}
System.out.println(); // 줄 바꿈
}
}
}*
* *
* * *
* * * *
* * * * *
upgrade ver.
public class Main {
public static void main(String[] args) {
int n = 5; // 피라미드의 높이
for (int i = 1; i <= n; i++) {
// 공백 출력
for (int j = 1; j <= n - i; j++) {
System.out.print(" ");
}
// '*' 출력
for (int k = 1; k <= 2 * i - 1; k++) {
System.out.print("*");
}
System.out.println(); // 줄 바꿈
}
}
}
배열(Array)
배열(Array)은 동일한 데이터 타입의 데이터들을 하나의 변수에 모아서 관리하는 자료 구조입니다. 자바에서는 기본형(primitive type)과 참조형(reference type) 모두 배열로 선언할 수 있습니다.
배열은 선언과 동시에 배열의 크기를 지정하거나, 먼저 배열을 선언하고 나중에 배열의 크기를 지정할 수 있습니다. 아래는 배열의 초기화 방법에 대한 예시 코드입니다.
// 배열 선언 및 크기 지정
int[] anArray = new int[10];
// 배열 선언과 동시에 초기값 지정
int[] anArray = {1, 2, 3, 4, 5};
배열의 각 요소(element)는 인덱스(index)를 통해 접근할 수 있습니다. 자바에서 배열의 인덱스는 0부터 시작합니다. 아래는 배열의 요소에 접근하는 방법에 대한 예시 코드입니다.
int[] anArray = {1, 2, 3, 4, 5};
// 배열의 첫 번째 요소에 접근
int firstElement = anArray[0];
// 배열의 두 번째 요소에 접근
int secondElement = anArray[1];
// 배열의 마지막 요소에 접근
int lastElement = anArray[anArray.length - 1];
자바에서는 다차원 배열(Multidimensional Array)도 지원합니다. 다차원 배열은 배열의 배열로 구성되어 있으며, 각 요소는 인덱스를 통해 접근할 수 있습니다. 아래는 2차원 배열의 예시 코드입니다.
// 2차원 배열 선언 및 초기화
int[][] twoDimArray = {{1, 2, 3}, {4, 5, 6}, {7, 8, 9}};
// 2차원 배열의 요소에 접근
int firstElement = twoDimArray[0][0];
int secondElement = twoDimArray[0][1];
int lastElement = twoDimArray[twoDimArray.length - 1][twoDimArray[twoDimArray.length - 1].length - 1];1. 배열의 크기 구하기
int[] anArray = {1, 2, 3, 4, 5};
int size = anArray.length;
System.out.println("Array size: " + size);
2. 배열의 요소 출력하기
int[] anArray = {1, 2, 3, 4, 5};
System.out.print("Array elements: ");
for (int i = 0; i < anArray.length; i++) {
System.out.print(anArray[i] + " ");
}
3. 배열의 요소 변경하기
int[] anArray = {1, 2, 3, 4, 5};
anArray[0] = 10;
anArray[4] = 50;
System.out.print("Array elements: ");
for (int i = 0; i < anArray.length; i++) {
System.out.print(anArray[i] + " ");
}
4. 배열의 요소 합 구하기
int[] anArray = {1, 2, 3, 4, 5};
int sum = 0;
for (int i = 0; i < anArray.length; i++) {
sum += anArray[i];
}
System.out.println("Array elements sum: " + sum);
5. 2차원 배열의 행(row) 합 구하기
int[][] twoDimArray = {
{1, 2, 3},
{4, 5, 6},
{7, 8, 9}
};
int[] rowSums = new int[twoDimArray.length];
for (int i = 0; i < twoDimArray.length; i++) {
int sum = 0;
for (int j = 0; j < twoDimArray[i].length; j++) {
sum += twoDimArray[i][j];
}
rowSums[i] = sum;
}
System.out.print("Row sums: ");
for (int i = 0; i < rowSums.length; i++) {
System.out.print(rowSums[i] + " ");
}
응용) 별모양 피라미드를 2차원 배열에 담아 차례로 출력하는 코드 예시입니다:
public class Pyramid {
public static void main(String[] args) {
int rows = 5; // 피라미드의 높이
char[][] pyramid = createPyramid(rows);
// 피라미드 출력
for (int i = 0; i < rows; i++) {
for (int j = 0; j < rows - i - 1; j++) {
System.out.print(" "); // 공백 출력
}
for (int j = 0; j < 2 * i + 1; j++) {
System.out.print(pyramid[i][j]); // 별 출력
}
System.out.println(); // 개행
}
}
// 별모양 피라미드 생성
public static char[][] createPyramid(int rows) {
char[][] pyramid = new char[rows][2 * rows - 1];
// 배열 초기화
for (int i = 0; i < rows; i++) {
for (int j = 0; j < 2 * rows - 1; j++) {
pyramid[i][j] = ' ';
}
}
// 피라미드 모양 설정
for (int i = 0; i < rows; i++) {
for (int j = 0; j < 2 * i + 1; j++) {
pyramid[i][rows - 1 - i + j] = '*';
}
}
return pyramid;
}
}
클래스(Class)

클래스는 객체 지향 프로그래밍 언어인 자바에서 사용되는 기본 단위입니다. 클래스는 객체를 생성하기 위한 템플릿으로, 객체의 상태를 나타내는 필드와 객체의 동작을 나타내는 메서드로 구성됩니다. 클래스를 사용하면 재사용 가능한 코드를 작성할 수 있으며, 객체 간 상호작용을 쉽게 관리할 수 있습니다.
클래스의 구성 요소는 다음과 같습니다:
- 필드 (Fields): 클래스 내에서 정의된 변수로, 객체의 상태를 나타냅니다. 필드는 클래스의 인스턴스 변수와 클래스 변수로 나뉩니다. 인스턴스 변수는 객체마다 고유한 값을 가지며, 클래스 변수는 클래스의 모든 인스턴스가 공유하는 값을 가집니다.
- 메서드 (Methods): 클래스 내에서 정의된 함수로, 객체의 동작을 나타냅니다. 메서드는 객체의 필드를 조작하거나 다른 객체와 상호 작용하는 데 사용됩니다.
- 생성자 (Constructors): 객체 생성 시 초기화를 담당하는 특별한 메서드입니다. 생성자는 클래스 이름과 동일한 이름을 가지며, 리턴 타입이 없습니다. 생성자를 통해 객체의 필드에 초기값을 할당하거나 객체 생성 시 필요한 작업을 수행할 수 있습니다.
- 중첩 클래스 (Nested Classes): 클래스 내부에 정의된 다른 클래스입니다. 중첩 클래스는 클래스 내부에서만 사용되는 경우나, 클래스와 밀접한 관련이 있는 경우 사용됩니다.
- 인터페이스 (Interfaces): 클래스가 구현해야 하는 메서드 집합을 정의하는 추상화된 틀입니다. 인터페이스를 구현한 클래스는 인터페이스에 정의된 메서드를 모두 구현해야 합니다.
클래스는 접근 제어자 (Access Modifiers)를 사용하여 다른 클래스와의 상호 작용 범위를 제한할 수 있습니다. 자바의 접근 제어자에는 public, private, protected 및 default(선언되지 않은 경우)가 있습니다.
자바 클래스를 정의하는 예시:
public class MyClass {
// 필드
private String myField;
// 생성자
public MyClass(String myField) {
this.myField = myField;
}
// 메서드
public String getMyField() {
return myField;
}
public void setMyField(String myField) {
this.myField = myField;
}
}위 예시에서, MyClass라는 이름의 클래스를 정의하였고, myField라는 이름의 필드와 생성자, getMyField와 setMyField라는 메서드를 가지고 있습니다.
위에서 정의한 MyClass 클래스를 사용하여 객체를 생성하고 메서드를 호출하는 예시는 다음과 같습니다:
public class Main {
public static void main(String[] args) {
// MyClass 객체 생성
MyClass obj = new MyClass("Hello, World!");
// 메서드 호출
System.out.println(obj.getMyField()); // 출력: Hello, World!
// 필드값 변경
obj.setMyField("Java is fun!");
System.out.println(obj.getMyField()); // 출력: Java is fun!
}
}위 예시에서 Main 클래스의 main 메서드 내부에서 MyClass의 인스턴스를 생성하고 있습니다. MyClass 객체를 생성할 때, 생성자에 문자열 "Hello, World!"를 전달하여 myField 필드를 초기화합니다.
그다음 getMyField 메서드를 호출하여 myField의 값을 출력하고, setMyField 메서드를 사용하여 myField의 값을 "Java is fun!"으로 변경한 후 다시 getMyField 메서드를 호출하여 변경된 값을 출력합니다.
클래스는 객체 지향 프로그래밍의 핵심 구성 요소이며, 클래스를 통해 캡슐화, 상속, 다형성 등 객체 지향 프로그래밍의 특징을 구현할 수 있습니다. 이러한 특징들을 사용하면 코드를 재사용하고, 유지 보수하기 쉽고, 확장성 있는 프로그램을 작성할 수 있습니다.
상속
상속은 객체 지향 프로그래밍의 중요한 개념 중 하나입니다. 상속은 기존 클래스를 확장하거나 재사용하여 새로운 클래스를 만드는 것을 의미합니다. 이를 통해 코드의 재사용성을 높이고 유지보수성을 향상할 수 있습니다.
자바에서 상속을 구현하는 방법은 extends 키워드를 사용하는 것입니다. 예를 들어, 다음은 Animal 클래스를 상속하는 Dog 클래스의 코드입니다.
public class Animal {
public void eat() {
System.out.println("Animal is eating");
}
}
public class Dog extends Animal {
public void bark() {
System.out.println("Dog is barking");
}
}
위 코드에서 Dog 클래스는 Animal 클래스를 상속하고 있습니다. 이를 통해 Dog 클래스는 Animal 클래스의 eat() 메서드를 상속받아 사용할 수 있습니다. 또한 Dog 클래스에서 bark() 메소드를 새로 추가하여 Dog 클래스에만 있는 기능을 구현할 수 있습니다.
public class Main {
public static void main(String[] args) {
Dog dog = new Dog();
dog.eat();
dog.bark();
}
}
상속을 사용하면 코드의 재사용성을 높이고 유지보수성을 향상할 수 있지만, 상속의 남용은 코드의 복잡성을 증가시키고 가독성을 해치는 원인이 될 수 있습니다. 따라서, 상속을 사용할 때는 상속의 목적을 명확히 하고, 클래스 간의 관계를 잘 파악하여 사용하는 것이 중요합니다.
상속의 한계는 다중 상속을 지원하지 않는다는 점입니다. 다중 상속은 여러 개의 클래스로부터 상속을 받는 것을 말합니다. 자바에서는 다중 상속을 지원하지 않는 이유는 다중 상속을 사용하면 코드의 복잡성이 증가하고, 클래스 간의 관계가 혼란스러워지기 때문입니다. 대신, 인터페이스를 사용하여 다중 상속과 유사한 효과를 구현할 수 있습니다.
따라서, 상속은 객체 지향 프로그래밍에서 중요한 개념 중 하나이며, extends 키워드를 사용하여 구현할 수 있습니다. 상속을 사용하면 코드의 재사용성을 높이고 유지보수성을 향상시킬 수 있지만, 상속의 남용은 코드의 복잡성을 증가시키고 가독성을 해치는 원인이 될 수 있습니다.
인터페이스(Interface)
인터페이스는 자바에서 객체의 사용 방법을 정의해 둔 타입으로, 객체의 교환성을 높여, 다형성을 구현하는데 중요한 역할을 합니다. 인터페이스는 개발 코드와 객체가 서로 통신하는 접점 역할을 하며, 코드가 인터페이스의 메서드를 호출하면 인터페이스는 객체의 메소드를 호출시킵니다. 이는 코드가 객체의 내부 구조를 알 필요가 없고 인터페이스의 메서드만 알고 있으면 된다는 장점을 가지고 있습니다.
인터페이스의 장점은 다음과 같습니다.
- 설계 단계에 인터페이스를 만들어 두면 설계 단계의 산출물과 개발 단계의 산출물을 효율적으로 관리할 수 있습니다. 개발할 때 메서드명, 매개 변수 명을 고민하지 않아도 되므로 개발자의 역량에 따른 메서드, 매개 변수 네이밍 차이를 줄일 수 있습니다.
- 인터페이스는 다형성을 구현하는데 중요한 역할을 합니다.
- 인터페이스는 객체 지향 개발에서 SOLID를 구현하는데 큰 도움을 줍니다.
인터페이스 예제:
// 인터페이스 정의
public interface Animal {
void makeSound();
}
// 인터페이스를 구현하는 클래스
public class Dog implements Animal {
@Override
public void makeSound() {
System.out.println("Woof!");
}
}
public class Cat implements Animal {
@Override
public void makeSound() {
System.out.println("Meow!");
}
}
// 메인 클래스
public class Main {
public static void main(String[] args) {
Animal myDog = new Dog();
Animal myCat = new Cat();
myDog.makeSound(); // 출력: Woof!
myCat.makeSound(); // 출력: Meow!
}
}@Override는 어노테이션(annotation) 중 하나로, 메서드가 상위 클래스나 인터페이스의 메서드를 오버라이딩(재정의)한다는 것을 명시적으로 나타냅니다. @Override 어노테이션을 사용하면 컴파일러가 해당 메서드가 정말로 오버라이딩 되었는지 확인할 수 있습니다.
만약, 상위 클래스나 인터페이스의 메서드를 제대로 오버라이딩하지 않았을 경우(예: 메서드명 오타, 매개변수 불일치 등), 컴파일러가 오류를 발생시켜 개발자에게 알려줍니다. 이를 통해 런타임 시 발생할 수 있는 문제를 미리 컴파일 시점에서 찾아낼 수 있습니다. 이렇게 @Override 어노테이션을 사용하면 코드의 가독성과 안정성이 향상됩니다.
위 예제에서 Animal이라는 인터페이스를 정의하고 있으며, makeSound라는 추상 메서드를 포함하고 있습니다. 그리고 Dog와 Cat 두 개의 클래스가 Animal 인터페이스를 구현합니다. 이렇게 인터페이스를 구현한 클래스들은 인터페이스의 추상 메서드를 모두 구현해야 합니다.
Main 클래스에서는 Animal 인터페이스를 구현한 Dog와 Cat 객체를 생성하고, 이 객체들을 Animal 타입의 변수에 할당합니다. 이렇게 하면 Animal 인터페이스를 구현한 클래스의 인스턴스를 동일한 방식으로 사용할 수 있습니다.
다음은 추가 인터페이스 예시 코드입니다.
public interface Shape {
double calculateArea();
double calculatePerimeter();
}위 코드는 Shape 인터페이스를 선언하는 코드입니다. Shape 인터페이스는 calculateArea()와 calculatePerimeter() 두 개의 추상 메서드를 선언합니다. 이 인터페이스를 구현하는 클래스는 반드시 이 두 메소드를 구현해야 합니다. 예를 들어, 다음은 Shape 인터페이스를 구현하는 Circle 클래스의 코드입니다.
public class Circle implements Shape {
private double radius;
public Circle(double radius) {
this.radius = radius;
}
@Override
public double calculateArea() {
return Math.PI * radius * radius;
}
@Override
public double calculatePerimeter() {
return 2 * Math.PI * radius;
}
}
위 코드에서 Circle 클래스는 Shape 인터페이스를 구현합니다. Circle 클래스는 calculateArea()와 calculatePerimeter() 메소드를 구현하고 있으며, 각각 원의 넓이와 둘레를 계산하는 메서드입니다.
인터페이스를 사용함으로써, Circle 클래스는 Shape 인터페이스를 구현하고 있음을 명확히 나타내며, 다형성을 구현할 수 있게 됩니다. 이제 다른 클래스가 Shape 인터페이스를 구현하면, 이 클래스와 Circle 클래스는 서로 다른 구현을 가진 calculateArea()와 calculatePerimeter() 메서드를 가지게 됩니다.
객체지향 프로그래밍(OOP) 맛보기!
먼저, 인터페이스를 정의합니다. 여기에서 Drivable 인터페이스는 drive() 메서드를 정의합니다.
interface Drivable {
void drive();
}
다음으로, Vehicle 클래스를 정의합니다. 이 클래스는 startEngine() 메서드를 가집니다.
class Vehicle {
void startEngine() {
System.out.println("The engine starts");
}
}
Car 클래스는 Vehicle 클래스를 상속받고, Drivable 인터페이스를 구현합니다. 이 클래스는 부모 클래스인 Vehicle의 startEngine() 메서드를 오버라이드하고, Drivable 인터페이스의 drive() 메서드를 구현합니다.
class Car extends Vehicle implements Drivable {
@Override
void startEngine() {
System.out.println("The car engine starts");
}
@Override
public void drive() {
System.out.println("The car drives");
}
}
마지막으로, 메인 클래스에서 Car 객체를 생성하고, 메서드를 호출하여 실행합니다.
public class Main {
public static void main(String[] args) {
Car car = new Car();
car.startEngine(); // The car engine starts
car.drive(); // The car drives
}
}이 예제에서 Vehicle 클래스와 Car 클래스는 클래스와 상속을 활용하고 있으며, Drivable 인터페이스를 구현하여 인터페이스를 활용하고 있습니다. 이를 통해 클래스와 인터페이스의 장점을 동시에 활용할 수 있습니다.
GitJav 멘토링 오프라인 활동사진







여러분의 지적과 피드백은 매우 소중합니다! 만약 제 코드나 설명에 대해
어떤 문제점이나 개선 사항이 있다면 언제든지 댓글로 남겨주세요. 감사합니다:)
'🏄🏻♂️ : activity' 카테고리의 다른 글
| GitJav 멘토링: 객체지향 프로그래밍 연습과 Git 라이프사이클 ep.5 (1) | 2023.05.24 |
|---|---|
| GitJav 멘토링: Java 기초 문법 총정리 및 Git 사용법 ep.4 (0) | 2023.05.17 |
| GitJav 멘토링: 자바 프로젝트 생성 및 구조, 조건문과 반복문 ep.2 (0) | 2023.04.19 |
| GitJav 멘토링: 자바의 변수와 자료형, 연산자 ep.1 (0) | 2023.04.12 |
| GitJav 멘토링: 오리엔테이션 ep.0 (0) | 2023.04.05 |